How Cosine trained Lumen Outpost for better AI agent behaviour: concise updates, honesty, planning, evidence, and action alignment.
The standard approach to model write-ups centres on capability. They ask what a model can solve, how hard the benchmarks are, and whether the model produces the right answer.
At Cosine, we think this is table stakes. That’s why, for Lumen Outpost, we focused on something developers feel much more often: behaviour.
In real software engineering workflows, the most frustrating model failures are often behavioral. The model may be technically able to complete a task, but still make the developer experience worse by being too verbose, narrating obvious steps, avoiding useful pushback, making claims without evidence, or saying it will do one thing and then doing another. The quality of interaction with an AI agent determines whether it will actually feel useful in serious work.
We have grouped these properties into a single term: “vibe”.
By vibe, we do not mean personality or polish, but the observable behavioral qualities that shape whether a model is effective in professional workflows: conciseness, timing, tone, honesty, evidence, planning, judgment, and alignment between stated intent and executed action.
Our approach consisted of five components:
1. Define a structured set of behavioral criteria, or “vibe-signals”
2. Construct a decomposed reward function over those signals
3. Separate penalties from rewards
4. Apply signals conditionally based on context
5. Train with reinforcement learning using multi-dimensional feedback
This approach produced a ~29.52% (6.7 pp) uplift in Vibe-Bench for Lumen Outpost compared with its underlying model, Kimi K2.6. Read our full report to see the benchmarks broken down.
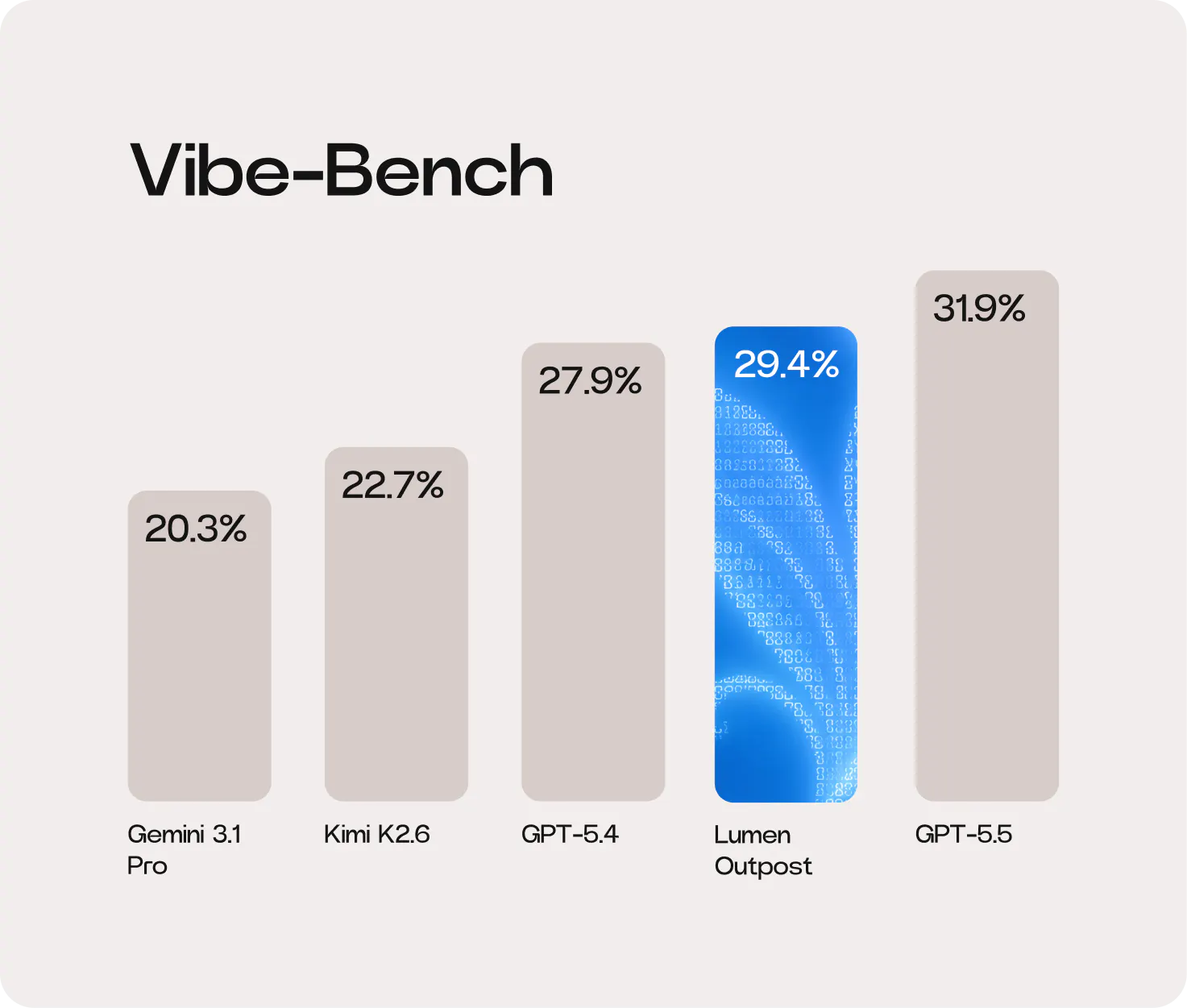
Behaviour matters as much as capability
To train models that adhere to consistent behavioral standards, we first needed to define those standards. Standard post-training pipelines optimise for correctness and helpfulness. Those objectives are necessary, but they leave much of the interaction space underspecified for effective post-training for AI behaviour.
They do not fully answer questions such as:
- When should the model provide a progress update?
- How much detail is enough?
- When should the model challenge an incorrect assumption?
- When should it ask a clarifying question?
- When is planning useful, and when is it just friction?
- How should the model balance confidence, evidence, and brevity?
With AI agents increasingly operating inside long-running, high-context workflows, these decisions matter. A model that can write code but constantly interrupts, over-explains, avoids disagreement, or misstates its next action becomes harder to trust. This is also why politeness is not the same as professional usefulness. Our solution was to define a structured rubric of behavioral signals. Each signal corresponds to an observable property of model output, with a clear definition of desirable behaviour and failure modes.
Instead of evaluating a response as one holistic output, we evaluate it across multiple dimensions.
The behavioral signals behind “vibe”
The primary signals used in training are summarized below.
| Category | Signal | Measurement |
|---|---|---|
| Communication | Update timing | Whether updates occur at appropriate phase boundaries |
| Communication | Conciseness | Whether responses maintain a high signal-to-noise ratio |
| Communication | Tone | Whether language remains neutral and professional |
| Communication | Action alignment | Whether actions match stated intent |
| Communication | Honesty | Whether the model challenges incorrect assumptions |
| Planning | Plan calibration | Whether planning behaviour matches task complexity |
| Planning | Evidence | Whether claims are supported by concrete verification |
These signals are derived from an internal evaluation framework that explicitly encodes both positive behaviour and corresponding violations. Vibe is not a vague preference, but a highly opinionated set of concrete behaviours – distilled from our extensive experience and user feedback across models – that can be evaluated, rewarded, penalized, and improved.
Turning behaviour into an optimizable objective
Once we had a set of behavioral signals, the next step was to translate them into a training objective. For this crucial step in LLM behaviour optimisation, we used a decomposed reward function in which each signal is weighted and evaluated individually, rather than relying on a single holistic score. This way, the model receives structured feedback showing which parts of its behaviour were desirable or undesirable.
If a response is correct but too verbose, the model receives that specific signal. If it is concise but fails to challenge an incorrect assumption, the feedback reflects that. This allows the optimisation to target specific failure modes, such as verbosity and action-intent mismatch, rather than treating them as undifferentiated errors.
For more on agent behaviour in real engineering workflows, read why we built an agent for engineers who use them every day.
Balancing rewards with constraints
We believe that not all behavioral signals should be treated symmetrically. Some behaviours are constraints that prevent harmful interaction patterns, but they should not be maximized.
For example, conciseness is important. But if conciseness is rewarded directly, the model may become too terse and omit useful details. Similarly, a professional tone is important, but rewarding tone too strongly can produce sterile or overly cautious responses. For that reason, we treat signals such as conciseness, tone, and timing primarily as penalties. If the model violates them, the reward decreases. Conversely, if it satisfies them, it simply meets the baseline.
Other behaviours are situationally valuable. Honesty, evidence, and planning judgment are not always required, but when the context calls for them, they significantly improve the interaction, and can receive positive reward when applied correctly.
This level of separation helps avoid pathological optimisation strategies:
- Rewarding conciseness too directly can produce under-explained answers
- Rewarding evidence too broadly can produce unnecessary citations or verification
- Rewarding planning too often can make simple tasks feel slow
- Rewarding deference can prevent the model from challenging bad assumptions
For us, good behaviour is applying the right behaviour at the right moment.
Smarter signal gating
To ensure behaviours are applied appropriately, signals are conditionally activated based on context.
Planning is a perfect example. For a complex codebase migration, a detailed plan is essential, but for a simple typo fix, it becomes a source of friction. A model that plans everything is naturally slower. The gating mechanism prevents the model from adopting rigid strategies, teaching it instead to recognise when a particular behaviour is expected.
How training for vibe transforms output
Optimising for these signals produced consistent changes in model behaviour. Responses became more concise while retaining necessary detail. The model reduced unnecessary narration and focused more directly on outcomes. It became more willing to challenge incorrect assumptions and more likely to support claims with concrete evidence.
In practice, this means the model is better at:
- Giving updates only when they are useful
- Asking clarifying questions when ambiguity matters
- Showing evidence when making verifiable claims
- Matching planning depth to task complexity
These improvements affect whether an AI system feels predictable and safe to use in real work. That connects closely to our broader view of developer-first AI agents.
Many aspects of interaction quality can be decomposed into measurable, optimizable components. While capability determines what a model can do, behavioral optimisation determines how effectively that capability is expressed.
For AI agents, this distinction is critical. In multi-step workflows, the model must solve while also making calibrated decisions, exposing uncertainty, and preserving user trust. We explored related challenges in our approach to Cosine’s Swarm mode, where coordination and visibility are central.
See the full Vibe-Bench results and how Lumen Outpost is redefining AI code quality.