How Cosine built a data engine for niche, legacy, and environment-constrained programming languages to improve Lumen Outpost.
Contemporary large language models (LLMs) demonstrate strong proficiency in widely used programming languages, such as Python and Java. However, generalization degrades significantly when these models are applied to niche, legacy, or environment-constrained languages. In these out-of-distribution (OOD) environments, training data is sparse, expertise is retiring, and verification is difficult.
Scaling model parameters alone does not resolve data scarcity. At Cosine, we treat this as an engineering problem. Rather than relying on static, human-annotated datasets, we have architected an automated synthetic data pipeline that produces executable, verifiable training trajectories grounded in deterministic execution.
Global infrastructure
Standard code-generation benchmarks disproportionately sample from modern web and data-science stacks. For instance, HumanEVAL and MBPP are exclusively Python-focused, whereas SWE-bench primarily evaluates models on GitHub issues in Python.
As models are optimised to score well on these specific benchmark tasks and because public scraping heavily favours the millions of open-source React and Node repositories, model performance is structurally skewed away from the languages that support critical industrial and financial infrastructure:
- COBOL: Maintains ~90% of global financial interactions. The codebase spans an estimated 800 billion lines of code, while demographic data indicates that 65% of the active engineering workforce will retire by 2029, creating a massive impending knowledge gap.
- ABAP: The proprietary language underpinning the SAP ecosystem, utilized by over 400,000 organisations. The impending 2027 maintenance deadline for legacy ECC systems necessitates large-scale automated migration to S/4HANA.
- Verilog: The primary hardware description language for the semiconductor industry, which produces >1 trillion units annually.
These domains suffer from a severe lack of high-quality, publicly available token volume, necessitating a novel approach to dataset construction.
Characterizing language scarcity
A key challenge in this domain is that data scarcity is not a single phenomenon. We classify language constraints along four parameters: engineer availability, human data feasibility, verification complexity, and public data availability.
| Metric | What it measures |
|---|---|
| Engineer availability | Size and accessibility of the talent pool capable of working on realistic production code |
| Human data feasibility | Throughput, the cost, and error risk of producing data via expert labelling |
| Verification complexity | Difficulty of enforcing objective correctness given tooling, runtimes, and dependencies |
| Public data availability | Availability of representative, executable, RL-usable public datasets |
This classification yields a five-tier spectrum for scarcity.
| Tiers | Description | Languages |
|---|---|---|
| 5 – Structurally scarce | Limited talent pools, complex runtimes, and minimal usable public data | COBOL |
| 4 – Severely constrained | Environment-coupled or legacy stacks with significant execution friction | Verilog, SystemVerilog, VHDL, Assembly, Fortran, Pascal, Visual Basic, D |
| 3 – Scarcity- constrained | Clear scarcity and higher complexity; manual approaches struggle to scale | Rust, OCaml, Solidity |
| 2 – Moderately constrained | Smaller or more specialised communities, higher review and verification costs | F#, Objective-C, Julia, Perl, Groovy, Lua |
| 1 – Least scarce | Large talent pools, simpler execution environments, and reasonable public data availability | Kotlin, Swift, Scala, C#, MATLAB, Dart, Shell, PowerShell, R |
This decomposition reveals that languages vary not only in the quantity of available data, but in the structure of that data. These distinctions inform the design of our data pipeline.
Our 8-step pipeline
To systematically improve performance across Tier 3-5 languages, we engineered an 8-step data pipeline. This architecture prioritizes deterministic verification over heuristic or LLM-as-a-judge validation.
Every example in our dataset is grounded in human-written code. We do not generate synthetic coding problems or tasks from scratch. Instead, we start with real pull requests, diffs, and commit pairs from production repositories, then apply a rigorous curation and validation pipeline to extract only the highest-signal examples.
Step 1: Extract real-world code changes
We began by targeting a broad set of repositories across languages and domains, ingesting real code changes written by human engineers. When real PRs are scarce, we derive synthetic pairs from human-authored commits, never from generated code.
Raw changes are then filtered through a multi-stage curation process. Heuristic screens that eliminate “slop” from the training data remove trivial edits. An automated classification system categorizes what remains by engineering use case – bug fix, refactor, feature development – so the dataset reflects the distribution of real software work.
Step 2: Construct reproducible execution environments
This is the hardest problem in data generation, and the place where most pipelines fail. We need every example to run deterministically, even for niche languages or large legacy monoliths with non-standard build systems and sparse documentation.
Our platform explores each repository with no prior knowledge of the build system and reverse-engineers the build and test process for the project. For languages without standard package managers, it extracts build logic from Makefiles, configuration files, and the codebase itself. It then enters an iterative build process: attempt, diagnose the failure, adjust, and retry until a deterministic environment is achieved. Only repos that build reproducibly survive.
Step 3: Validate with executable correctness checks
Every example includes an objective correctness signal. Existing tests are validated. When tests are absent, we synthesize a regression test that passes on the fixed code and fails on the original. Each test is executed in an isolated environment to confirm that the pass-on-head / fail-on-base property holds. Examples that fail this check are discarded.
Step 4: Generate natural-language task descriptions
We transform code diffs into human-sounding problem statements. Our proprietary generation system reads the patch and produces an instruction that sounds like it came from a GitHub issue or PR description. These statements are natural, actionable, and tailored to the language and codebase. A Rust issue reads differently from a Python one, and both read as if written by a human engineer.
Step 5: Enrich with repository context
Models edit code more effectively when they understand the codebase's conventions. We analyse each repository to extract coding guidelines, style conventions, and architectural patterns. We also quantify each change's structural complexity, measuring how much the patch alters the code's shape. This contextual encoding is critical for teaching models the “vibes” of expert reasoning.
Step 6: Build a difficulty-ranked curriculum
Not all examples are equally difficult. We rank each task by structural complexity, test coverage, and codebase familiarity. During training, examples are presented in a curated order (easier tasks first, harder tasks later), which accelerates convergence and improves final model performance.
Step 7: Assemble and validate
All outputs are combined into a unified dataset where each row includes a natural-language task description, the golden patch, the test patch, a reproducible execution environment, and the validated correctness signal. Before anything ships to training, it undergoes our multi-layer validation protocol: reproducibility checks, metadata verification, and golden-patch validation against the synthesized test.
Step 8: Continuous data generation
Because validation relies on deterministic execution rather than human review, the pipeline can run continuously to generate new data. This enables us to scale data production across languages and domains, including those where manual data collection is infeasible. In practice, we can generate thousands of high-quality examples per language tier, with distributional properties that mirror real-world usage.
How grounded training changes model behaviour
Training on execution-grounded trajectories fundamentally alters policy behaviour. Rather than memorizing token co-occurrences, the model learns a generalized search-and-verification policy.
Evaluation demonstrates:
1. OOD Robustness: the model successfully navigates novel syntax and constrained toolchains
2. Self-Correction: exposure to deterministic failure states during RL improves iterative debugging
3. Cross-Tier Generalization: algorithmic reasoning improvements in Tier 3 languages demonstrate transfer to Tier 4 and 5 tasks
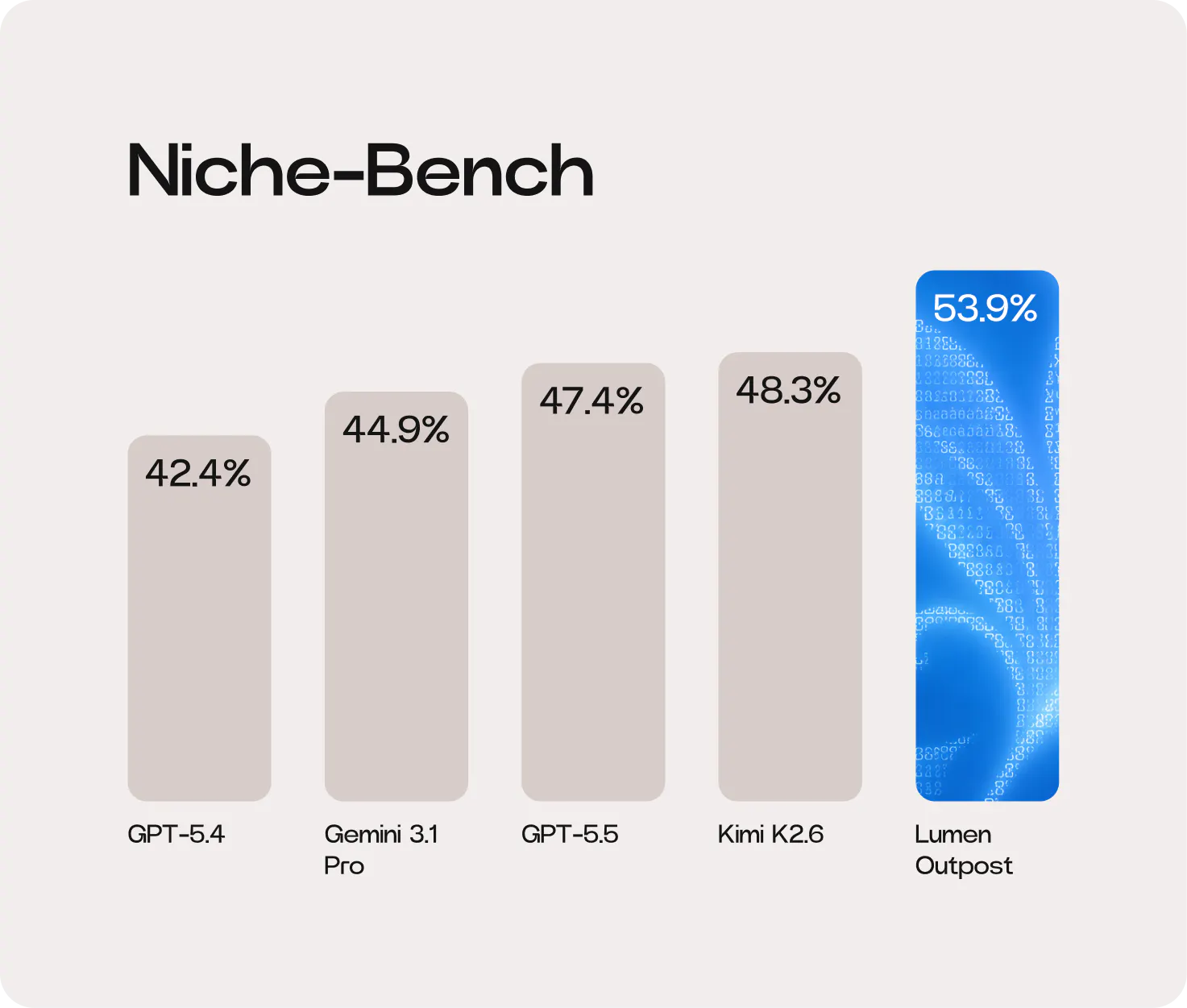
This architecture yielded an ~11.6% (5.6 pp) performance uplift for our Lumen Outpost model (benchmarked against its base model on Niche-Bench), beating frontier models like GPT-5.5 and Gemini 3.1 Pro.
Overcoming the data scarcity barrier in legacy and niche programming languages requires more than just additional data. By engineering a pipeline that treats execution as the primary supervision signal, we can generate high-fidelity, RL-ready datasets at scale. This infrastructure enables the reliable deployment of AI-assisted engineering to the critical systems underpinning the global economy.
For further information on our agent architectures, explore our research.