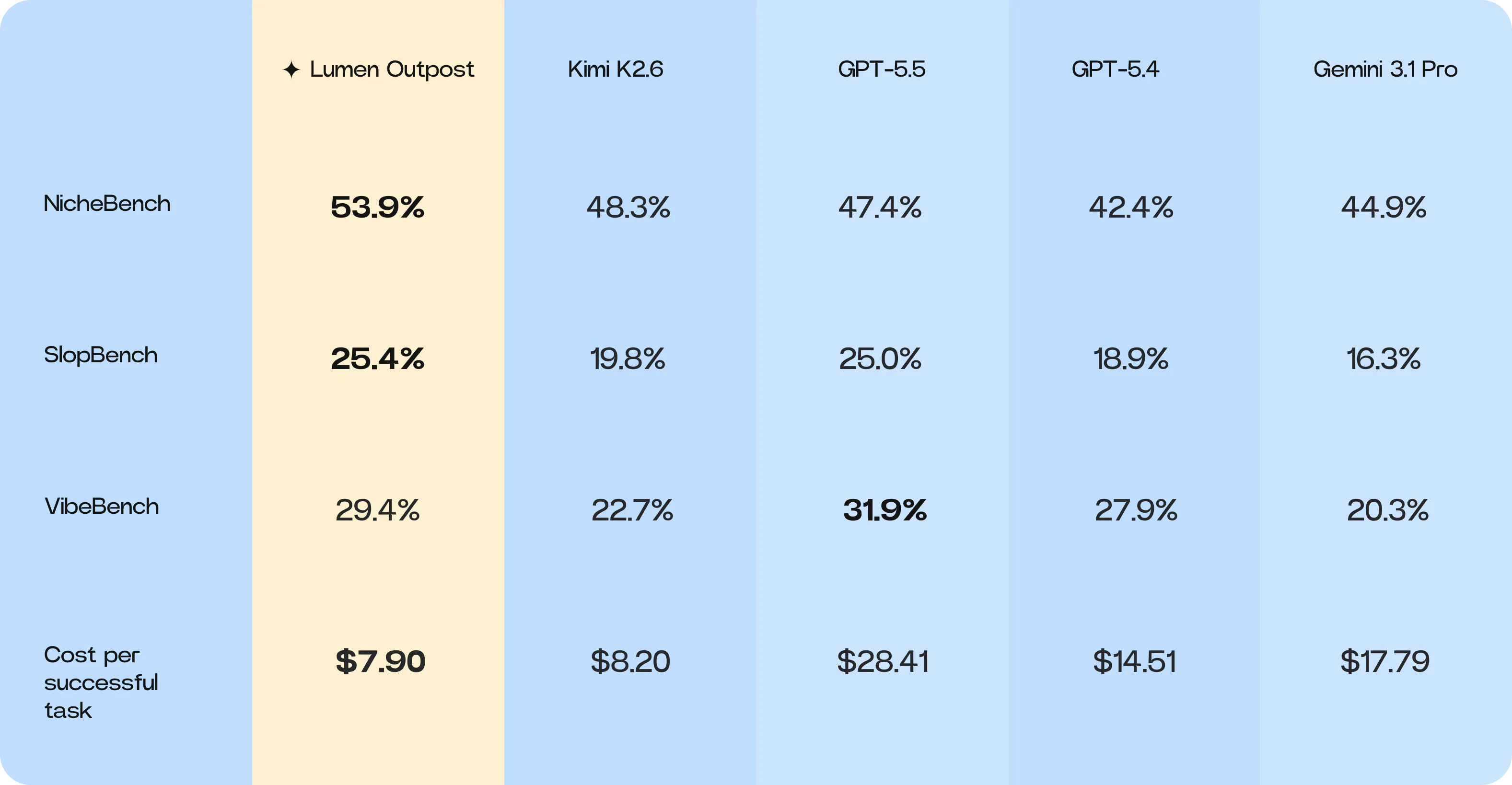
Benchmark results for Lumen Outpost across Niche-Bench, Slop-Bench, Vibe-Bench, and cost per successful coding task.
This report presents a comparative analysis of Cosine’s Lumen Outpost model against 4 models: Kimi K2.6 (its base model), GPT-5.5, GPT-5.4, and Gemini 3.1 Pro. We evaluated all models on highly complex, long-horizon coding tasks in 13 different coding languages.
A core objective of our work with Lumen Outpost is to demonstrate the viability of highly targeted post-training. We chose to specialise this model not just in raw coding accuracy, but in specific behavioral signals, such as agent initiative, planning, and update substance.
Proving that we can successfully steer these qualitative traits through post-training is a critical milestone for our future work on Sovereign AI. Specifically, these techniques form the foundation for the upcoming Lumen Sovereign model, which we are building with GPU support from the UK Government.
Our central findings are that post-training demonstrably transforms capability. Across the board, Lumen Outpost outperformed its base model, Kimi K2.6, demonstrating our ability to push models towards the frontier. Critically, this was also achieved while reducing the cost per successful task.
Niche-Bench performance
Niche-Bench is an internal evaluation benchmark for assessing performance improvements of models in niche, legacy, or environment-constrained programming languages, in contrast to standard benchmarks focused on Python. Niche-Bench represents a cross-language coding benchmark environment with 750 selected slots for evaluation.

The ~11.6% jump in Pass@3 for Lumen Outpost over Kimi K2.6 suggests that Lumen Outpost has a stronger capability for self-correction or alternative pathfinding when initial attempts fail, relative to Kimi K2.6's baseline. This shows that our targeted post-training for Lumen Outpost has unlocked new levels of performance in challenging, non-Python environments.
Niche-Bench language-specific breakdown
Lumen Outpost leads or ties in 9 of the 13 languages assessed.
Key winners for Lumen Outpost were in functional and high-context software logic.
- Fortran: +11.0pp (63.2% vs 52.2%)
- ABAP: +11.3pp (31.3% vs 20.0%)
- Java: +12.9pp (76.5% vs 63.6%)
- Rust: +18.1pp (55.6% vs 37.5%)
These languages, which span procedural (Fortran), functional (Rust), and object-oriented (ABAP, Java) environments, have shown significant improvement. Our post-training emphasis on scope discipline and action alignment heavily penalizes tentative, incomplete code blocks. Lumen Outpost has learned to construct complete, architecturally sound solutions in a single pass.
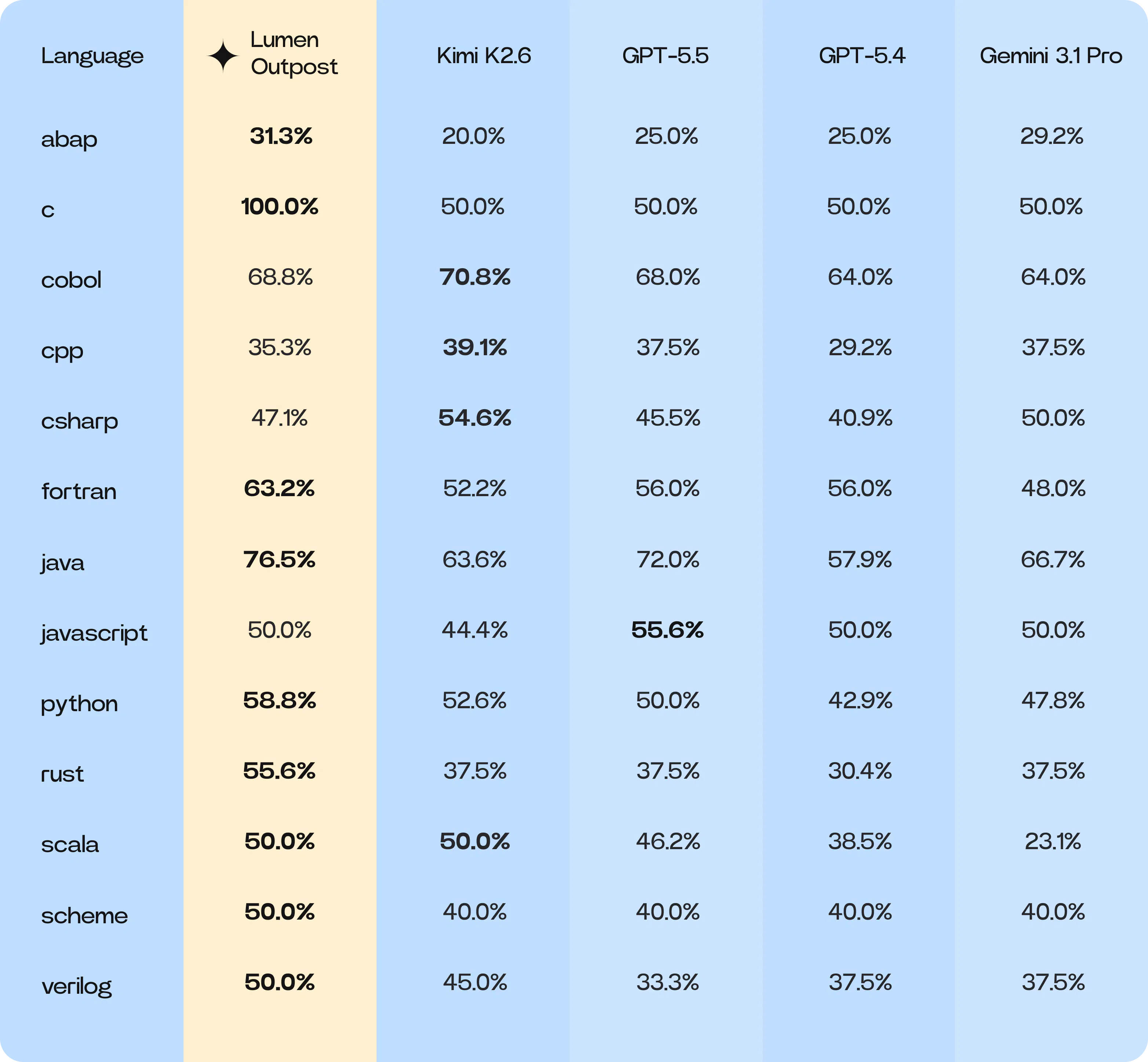
An interesting insight during the training for Lumen Outpost was its performance on COBOL. Lumen Outpost scored 68.8%, a regression from the Kimi K2.6 baseline of 70.8%. This dip signals that our highly targeted post-training, which successfully optimised for scope discipline and single-pass, architecturally sound solutions in modern environments, inadvertently penalized COBOL's unique procedural nature.
Slop-Bench performance
Slop-Bench is an internal benchmark evaluation designed to measure the reduction of coding “slop”, or low-quality changes, introduced by AI models into a codebase. This evaluation focuses on critical long-term code-quality criteria, such as maintainability, clean integration with the existing architecture, and minimizing complexity.
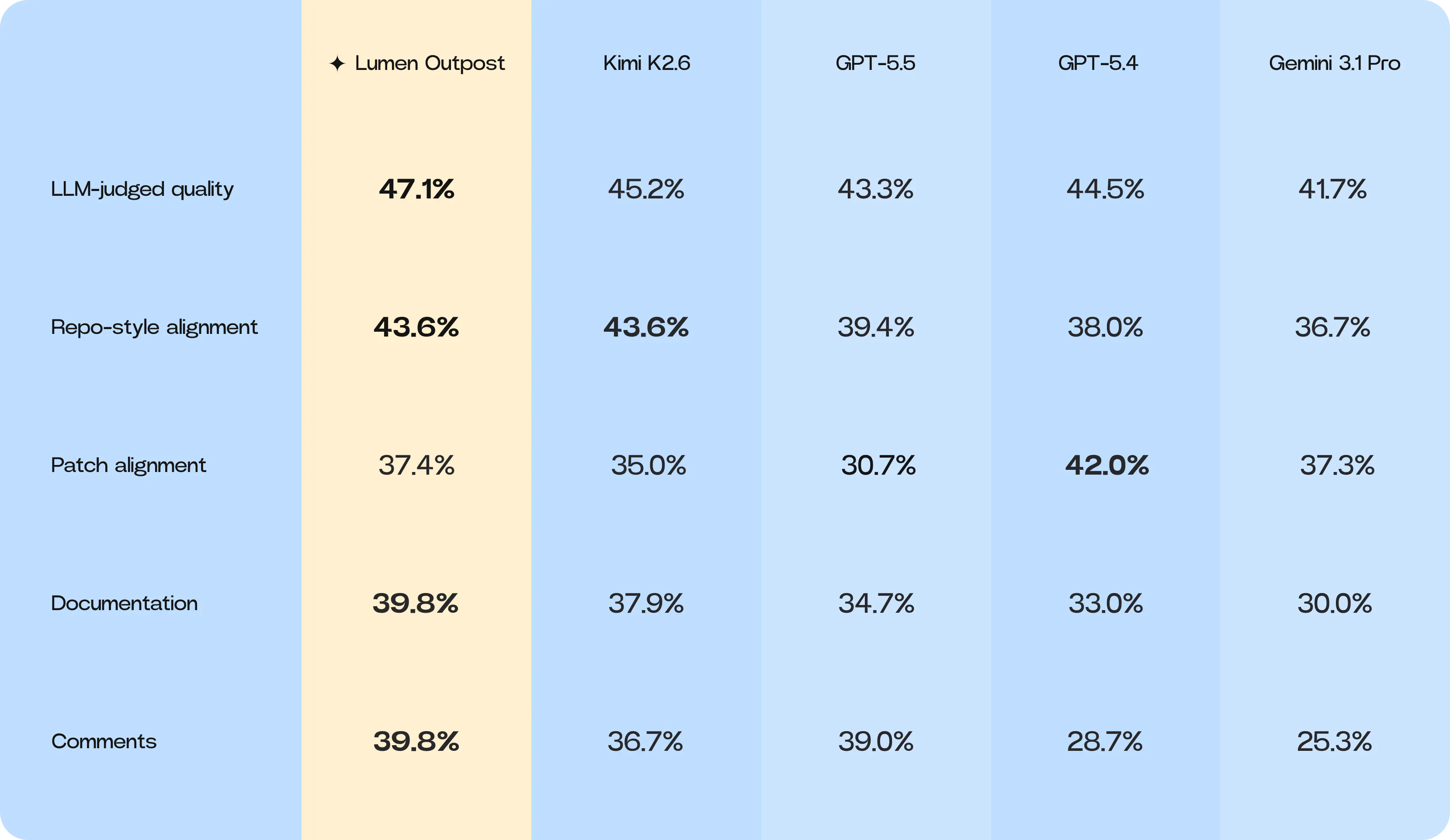
In this latest run, Lumen Outpost led the aggregate slop-quality score, signaling a meaningful shift towards cleaner implementation behaviour. While the margin over GPT-5.5 is narrow, the gap between Lumen Outpost and its base model, Kimi K2.6, is significant.

Lumen Outpost achieved the top rank in LLM-judged implementation quality, suggesting that the model is not merely finding lucky patches that pass tests, but is generating code that appears more aligned and maintainable. Notably, the training process for Lumen Outpost did not sacrifice the strengths of its base model; it preserves Kimi K2.6’s high sensitivity to repo-style alignment while simultaneously improving the broader slop profile. This improvement extends to smaller but highly visible developer details, such as documentation and comment quality, where Lumen Outpost leads.
Vibe-Bench performance
Vibe-Bench is a specialised benchmark designed to measure and optimise the behavioral qualities of AI models – referred to as “vibe” – in professional workflows, such as conciseness, honesty, and appropriate planning. It uses a structured rubric of “vibe-signals” and a decomposed reward function to move beyond traditional capability metrics, ensuring AI agents are effective and trustworthy, and that they integrate smoothly into high-context engineering processes.
The results indicate that Lumen Outpost is successfully shifting from Kimi K2.6's weaker interaction profile towards the collaborative style of GPT-5.5, a move directly supported by the strong implementation-quality signals our developers value.

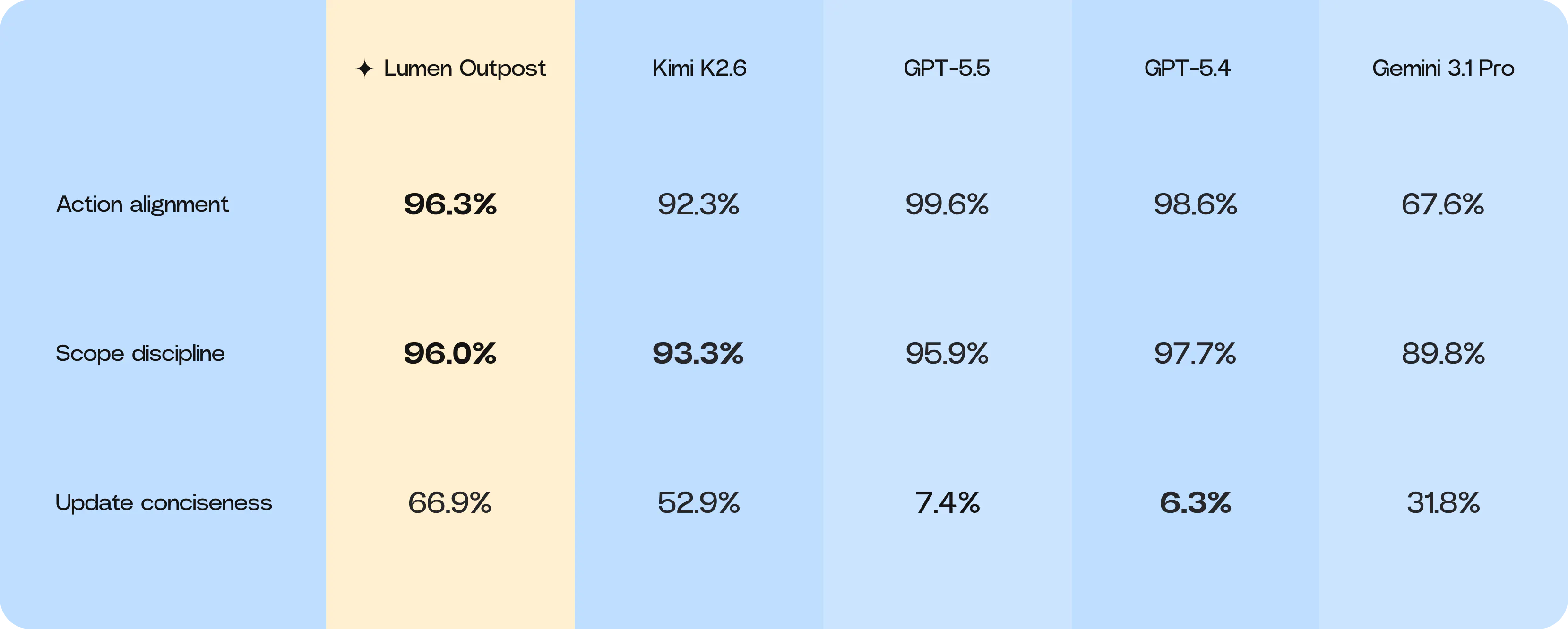
Lumen Outpost has shown significant growth in specific behavioral signals that matter most to developers. It is highly action-aligned, effectively translating user requests into concrete work. In terms of scope discipline – the ability to stay on task without modifying unrelated files – Lumen Outpost has reached parity with GPT-5.5. Furthermore, Lumen Outpost has developed a useful middle ground in communication: it is far more concise than GPT-style models, providing signals without becoming noisy.
Cost per successful task
As enterprise adoption of AI agents accelerates, inference costs are becoming a growing focus. While frontier models from Anthropic and OpenAI continue to advance capabilities, their pricing structures can make production-scale deployment prohibitively expensive for many engineering teams.
To evaluate real-world economic performance, we measured the cost per successful task across all benchmarked models. This analysis incorporated:
- Average input, cached input, and output tokens consumed per task
- Retail pricing for input, cached input, and output tokens
- Average total inference cost per task
- Adjustment by each model’s average successful task rate
This methodology provides a more representative measure of practical engineering value than raw token pricing. Lower token prices do not necessarily translate into lower operational costs if a model requires multiple failed attempts, produces incomplete implementations, or generates excessive low-quality output.
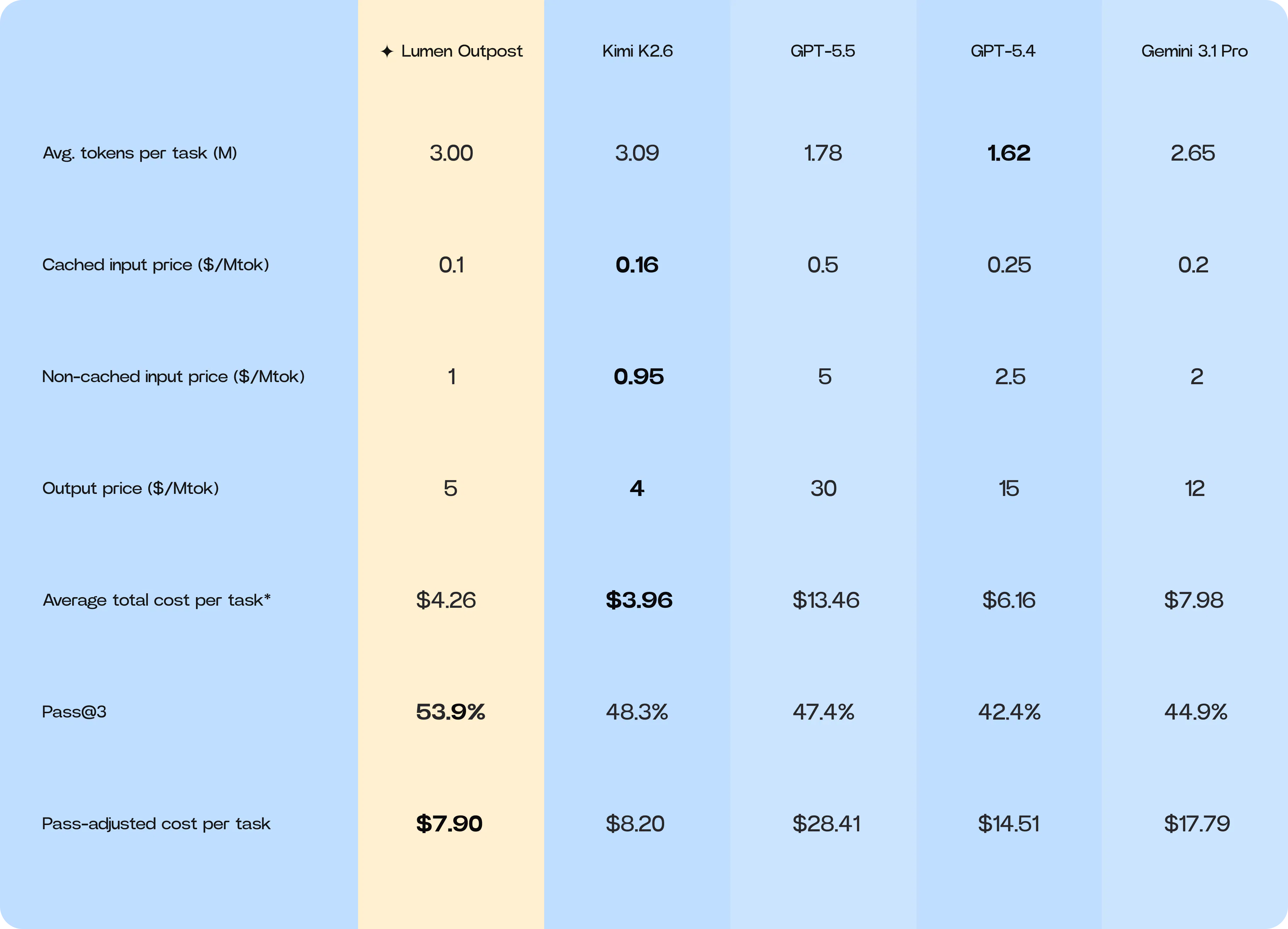
*Weighted average based on mix of input / cached input / output tokens, which varies by model.
Our findings show that Lumen Outpost delivers the strongest cost-efficiency profile among the models evaluated. While Lumen Outpost consumes more average tokens per task than GPT and Gemini models, partly due to its smaller context window, this is offset by substantially lower output-token pricing and a higher effective success rate.
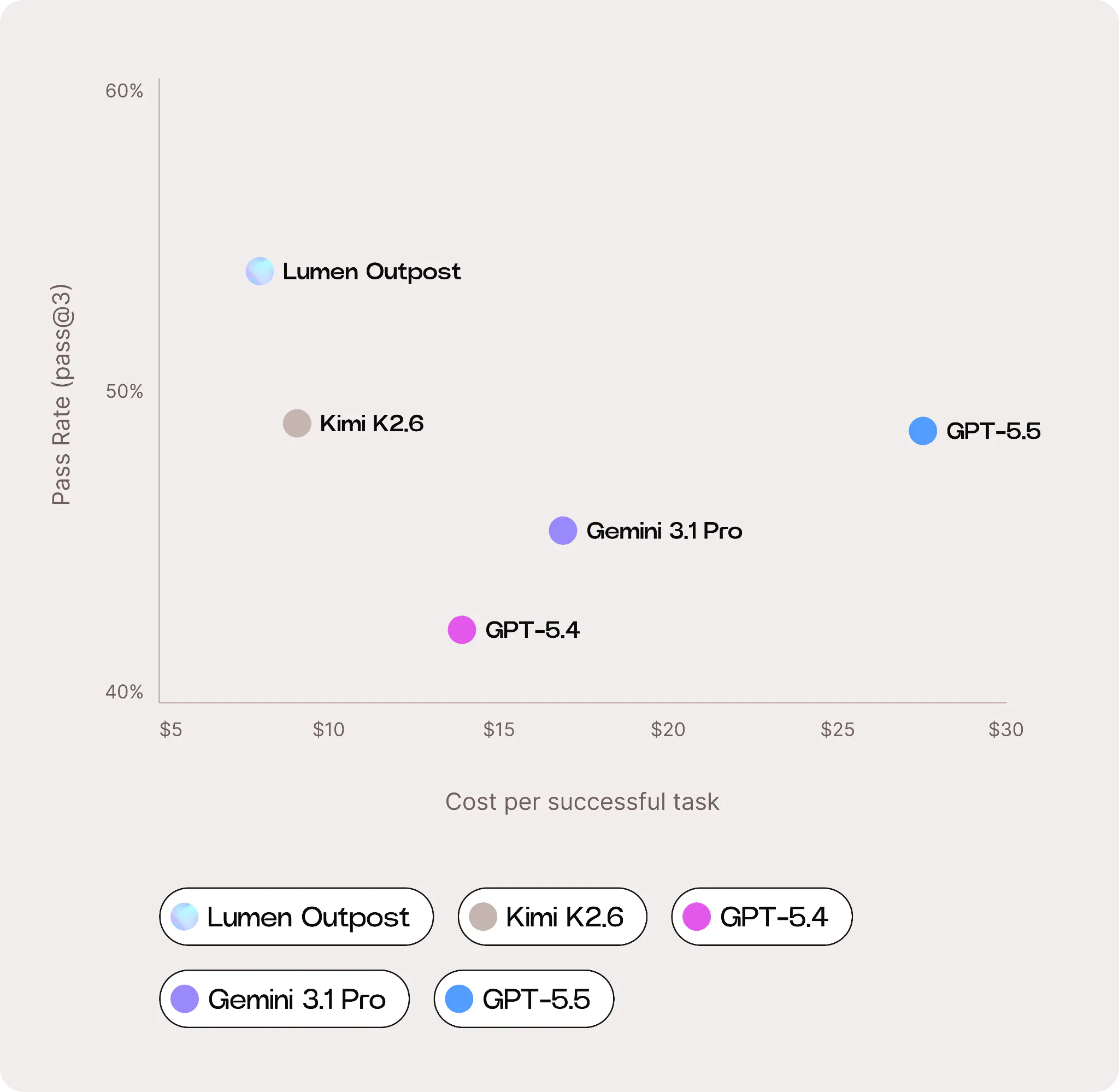
The result is a materially lower cost per successful engineering task, allowing teams to achieve frontier-level coding performance without frontier-level inference spend.
Summary
This report on our Lumen Outpost benchmarking shows the capabilities of highly targeted post-training. Lumen Outpost consistently outperformed its base model, Kimi K2.6, and established itself alongside frontier models across both quantitative and qualitative metrics, particularly for complex, long-horizon coding tasks.
The key findings demonstrate a successful specialisation:
- Niche-Bench Performance: Lumen Outpost leads all tested models in overall performance with a pass score of 53.9%. The model shows significant gains in languages such as Fortran (+21.1%), ABAP (+56.5%), and Java (+20.3%), driven by its improved ability to construct complete, architecturally sound solutions.
- Slop-Bench Performance: The model achieved the highest Aggregate Slop-Quality score (25.4%), demonstrating a meaningful shift towards cleaner, more maintainable code generation. This is reinforced by top scores in LLM-judged quality (47.1%) and in developer-critical details such as documentation and comments (39.8%).
- Vibe-Bench Performance: Lumen Outpost successfully shifted its interaction profile, achieving high Action alignment (96.3%) and parity in Scope discipline (96.0%). It offers a superior developer experience by providing concise updates (66.9%) while maintaining the behavioral signals that ensure smooth integration into high-context engineering workflows.
- Cost per successful task: Lumen Outpost delivers the strongest cost-efficiency profile at $7.90 per successful task. This is achieved by offsetting higher token consumption with substantially lower output-token pricing and a higher effective success rate.
Lumen Outpost represents a proven blueprint for engineering success, demonstrating a direct path to cleaner, more cost-efficient code generation in complex environments. These results form the direct technical foundation for our next major milestone: the Lumen Sovereign model.