Introducing Lumen Outpost, Cosine’s targeted post-trained coding model built to reduce slop, improve behaviour, and strengthen performance in niche languages.
If you are already using coding agents, the benefits are obvious. You implement code faster, gain leverage, and once you start working this way, it is hard to go back.
But there are equally obvious problems. In our conversations with developers, the feedback we heard about coding agents was remarkably consistent. The models are capable, but they can be deeply frustrating to work with in practice.
Code often works, but it’s riddled with slop: messy patches, duplicated logic, and unnecessary abstractions that rot a codebase over time. The interaction is often irritating, overly verbose, overconfident, and sycophantic. Performance drops off a cliff as soon as you move into niche languages outside the mainstream.
The impact of this is more damaging than most realise. Six months down the road, is the AI code maintainable? How much time is lost going back and forth with an overly polite agent who says tasks are complete before they actually are?
For our latest round of reinforcement learning on Kimi K2.6, we decided to take these issues seriously and train directly against them. The result is Lumen Outpost.
Benchmarks
Most industry benchmarks measure whether a model can solve an isolated problem, but that isn’t how code needs to operate in real-world production environments. They don’t assess whether the model acts like a good colleague or whether the code it writes will be maintainable six months later.
To evaluate Lumen Outpost, we examined three new internal benchmarks: Niche-Bench (legacy-language robustness), Slop-Bench (maintainability), and Vibe-Bench (collaboration). We trained on three specific pillars for Lumen Outpost, using RL with explicit signals for code quality, behaviour, and robustness across languages.
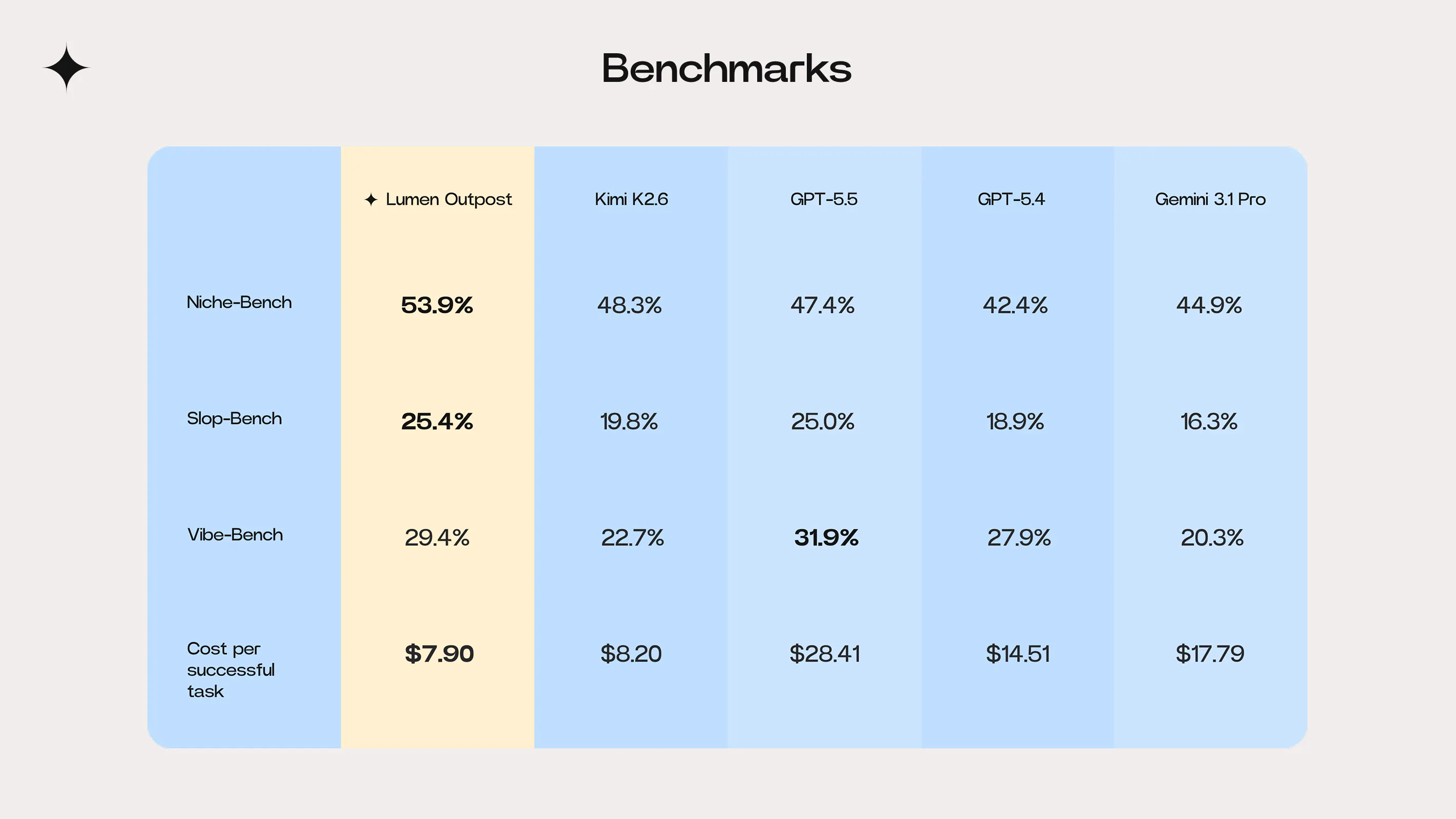
As a result, Lumen Outpost now leads the field in niche language performance (Niche-Bench) and code maintainability (Slop-Bench), while demonstrating a near-frontier level of collaborative behaviour (Vibe-Bench).
With Lumen Outpost, engineers get cleaner code, more consistent interactions, and significantly better performance in constrained environments. Read the Lumen Outpost Benchmark Report for the full benchmark results.
Three pillars of training
Typically, AI models try to be everything to everyone, offering generalist responses and outputs. We’ve decided to do the opposite, building our Lumen models to do one thing: write exceptional code.
At Cosine, our thesis is simple. A model trained exclusively on real production code from real engineering teams will always outperform a generalist on the tasks developers actually need.
Every training decision we made is centred on a single objective: better code. These are the three pillars of how we trained Lumen Outpost:
1. Mastering niche languages
We started with a structural issue. Specialised languages like COBOL, ABAP, Fortran, and Verilog underpin the world’s most critical infrastructure, yet they receive almost no attention in AI training.
Most models perform well on widely used languages because that is where the data is. As soon as you move into more specialised environments, performance becomes unreliable.
That’s why we built our data pipeline to generate large volumes of verifiable, executable tasks from human-written sources. Lumen Outpost delivers a material uplift in performance for the languages that drive the global economy, leading or tying in 9 of the 13 languages assessed.
Lumen Outpost achieved a score of 53.9% on Niche-Bench, outperforming frontier models such as GPT-5.5 and Gemini 3.1 Pro.
Discover how we trained for niche languages.
2. Eliminating slop
Generalist models are trained to pass short-term tests, optimising for immediate correctness. But that doesn’t address whether the code remains clean, maintainable, and consistent with the rest of the system over time.
We talk to developers daily, and the pain points are clear. Code that looks fine at first but is built in isolation gradually becomes brittle and hard to work with. Vibe-coded systems slowly accumulate complexity, introduce subtle bugs, and create growing backlogs.
Lumen Outpost was explicitly trained to counter this dynamic. We penalized unnecessary complexity, duplication, and dead code. We rewarded minimal, disciplined changes that respect the structure of the existing codebase.
In our post-training evaluation, Lumen Outpost achieved a leading score of 25.4% on Slop-Bench, demonstrating cleaner, more maintainable implementation behaviour.
Read our deep dive into reducing code slop.
3. Perfecting the vibe
A lot of the friction in using AI comes from how it behaves, not necessarily from what it produces. We grouped these behaviours – scope discipline, update conciseness, and action alignment – under the concept of “vibe”.
Using behavioral RL, we trained Lumen Outpost to deliver high-signal updates, challenge incorrect assumptions, and ensure that its stated intentions always align with its actual code changes.
Our post-training improved the Kimi K2.6 baseline performance for Lumen Outpost from 22.7% to 29.4% on Vibe-Bench. This significant jump brings the model closer to the performance of frontier-level models like GPT-5.5, a key milestone our engineers value.
The model is easier to work with. Less filler, more clarity, and better judgment about when to step in as a competent colleague would.
Explore how we’ve been training for vibe.
Lumen Outpost in action
The most cost-efficient model available
We also recognise that cost efficiency is becoming increasingly important for developers deploying AI agents in production. We therefore benchmarked Lumen Outpost against frontier peers not only on capabilities but also on cost per successful task.
To do this, we evaluated average input, cached input, and output token usage per task, retail token pricing, and overall task success rates across the benchmark suite.
We found that Lumen Outpost is the most cost-efficient model we evaluated, delivering more than 3x greater cost-efficiency than GPT-5.5. While Lumen Outpost uses more tokens per task than some GPT and Gemini models, its substantially lower output-token pricing and stronger effective pass rate result in a meaningfully lower overall operational cost.
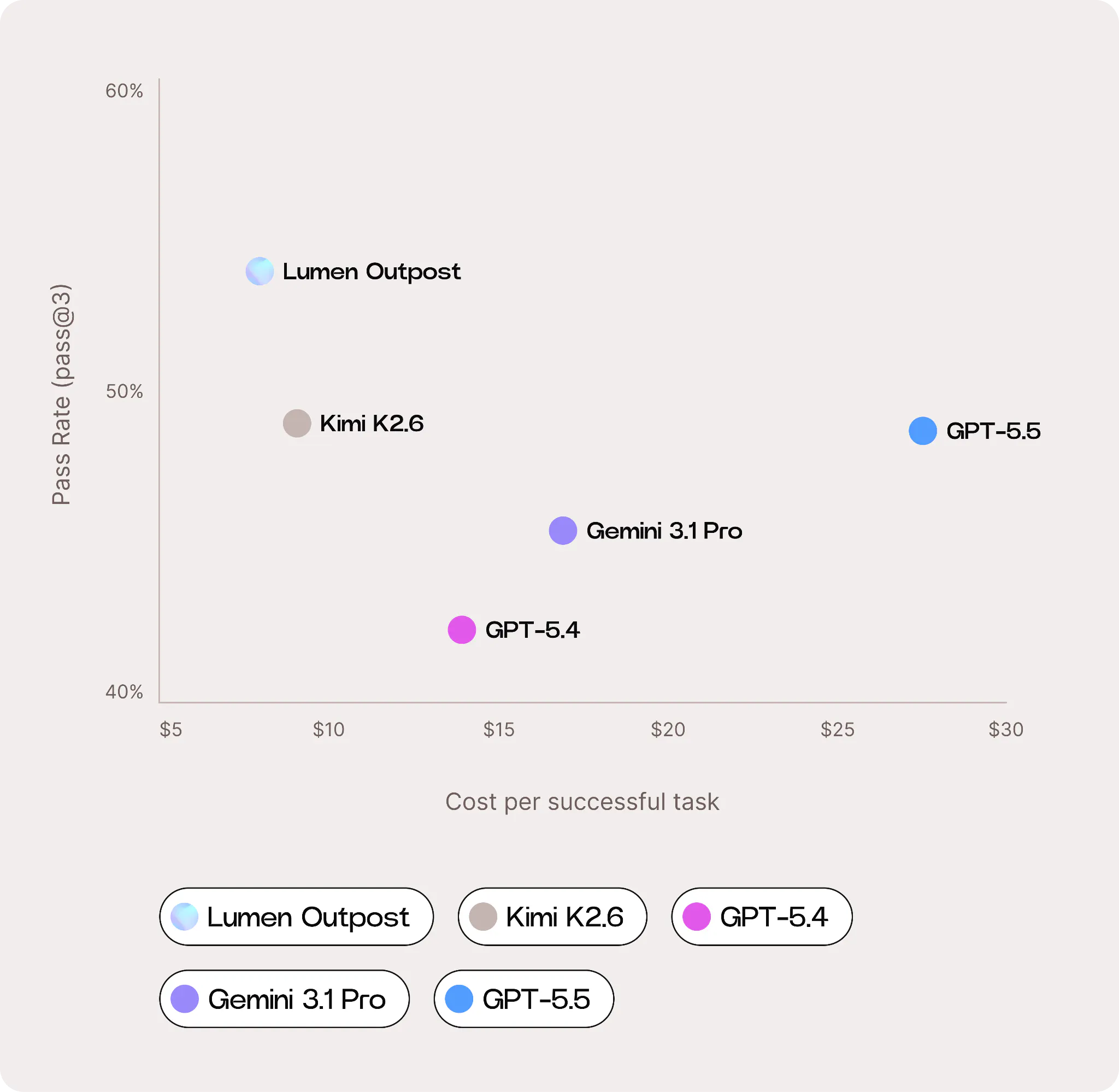
Read the Lumen Outpost Benchmark Report for the full benchmark results and cost-efficiency breakdown.
Available now
We're introducing Lumen Outpost with a simple challenge for developers: try it.
Our post-trained coding agent models are now available on the Cosine surfaces. For custom deployment, get in touch with us.