How Cosine trained Lumen Outpost to reduce AI slop by optimising for maintainability, architectural fit, and long-term code quality.
When prioritising AI code quality, we have observed that models are typically optimised to pass short-term tests. They are trained to produce outputs that satisfy immediate correctness criteria, such as passing a unit test or matching a specific output.
However, they are rarely trained to pass the long-term tests that actually matter to engineers and are essential for maintainable AI code:
- Is the code maintainable?
- Does it integrate cleanly with the existing architecture?
- Does it avoid degrading the system over time?
This mismatch leads to predictable failure modes. A model can repeatedly pass local tests while gradually increasing complexity, introducing duplication, and accumulating low-quality changes that only become visible at scale. In the AI world, this is referred to as “slop”.
At Cosine, we chose to treat reducing AI slop as a first-class training problem in our latest round of reinforcement learning for Lumen Outpost. Rather than optimising only for whether code works, we explicitly optimised for how it is written and integrated into an existing system.
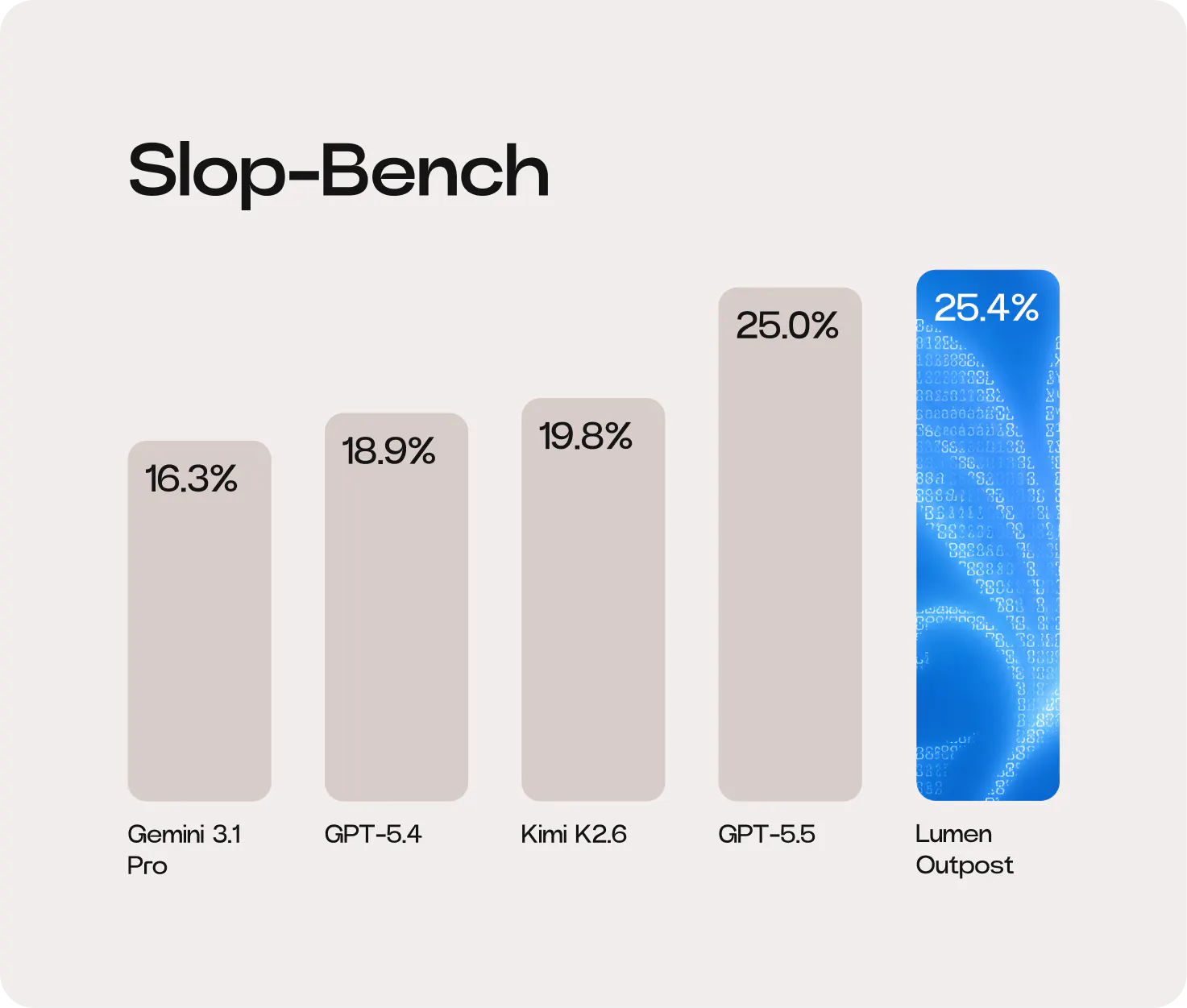
Our approach delivered a ~28% (5.6 pp) uplift on Slop-Bench for our Lumen Outpost model compared to its underlying model, Kimi K2.6. See the full benchmarking here.
Working code still isn’t good enough
In many coding systems, success is defined as passing a test suite. While necessary, this definition is incomplete. It allows a wide range of low-quality solutions to be treated as equally valid.
We observed several recurring failure modes in which models would generate larger-than-necessary patches, reimplement existing functionality, or introduce incremental complexity, making the system harder to maintain. These behaviours can be subtle in isolation, but they compound over time.
A broader observation is that models can appear highly capable in benchmarks while quietly degrading real codebases.
To address this, we decomposed abstract ideas of clean code into measurable dimensions. Each signal corresponds to a specific failure mode we wanted to eliminate:
- Structural Complexity: penalizing unnecessary branching, deep nesting, or over-engineering
- Redundancy & Duplication: detecting when a model introduces new logic where existing internal utilities would suffice
- Dead Code: ensuring no unused variables, imports, or vestigial logic are left behind
- Pattern Deviation: measuring how well the edit aligns with established conventions in the surrounding codebase
By isolating these behaviours, we can target them directly during reinforcement learning.
Penalizing complexity, rewarding context-aware edits
We treat most slop-related signals as penalties. Even if a model completes the primary task successfully, the overall reward is reduced if it introduces regressions in code quality.
This formulation reflects the developer’s reality: technical debt is not a neutral trade-off. By penalizing these behaviours, the model learns that the easiest path to passing a test – such as copy-pasting a function instead of importing it – is actually a high-cost strategy.
Conversely, we reward behaviours that reflect disciplined engineering. This includes:
- Producing minimal patches
- Reusing existing abstractions
- Alignment with surrounding architecture
Importantly, these rewards are context-dependent. What constitutes a minimal or appropriate change depends entirely on the existing environment. As a result, evaluation must consider the relationship between the existing code and its environment.
Evaluating in context
Many quality issues are invisible in isolation. A function might look perfect in a vacuum, but be a duplicate of a functionality that already exists elsewhere. Similarly, a change may pass tests but violate established patterns or unnecessarily increase complexity.
To capture these effects, we evaluate model outputs within reconstructed environments that include the surrounding codebase. This allows us to measure properties like reuse and integration quality that standard benchmarks miss.
For those interested in how we manage this at scale, our Swarm mode offers a deeper dive into optimising models to enable long-horizon agents to complete complex coding tasks end-to-end over extended execution periods.
The training loop
These signals are incorporated into a reinforcement learning framework.
1. The model generates candidate code edits
2. The edits are verified for correctness
3. The edits are graded for quality
4. The final reward combines both, shifting the model towards policies that satisfy both objectives simultaneously
From task completion to codebase contribution
Training against slop means treating code quality as a first-class objective. By defining structured signals, penalizing waste, and rewarding discipline, we produce models that don’t just seek to complete tickets but also contribute positively to lived-in systems in the long term.
The role of AI in engineering is shifting from a tool that merely automates typing to a system that understands the value of a maintainable codebase, and Lumen Outpost is our first step towards delivering that.
See the full Slop-Bench results and how Lumen Outpost is redefining AI code quality.