Benchmarking specialist programming languages reveals a major blind spot in AI coding. Cosine shares early results across ABAP, COBOL, Rust, and Verilog, and explains why niche enterprise languages need better evaluation.
The modern world does not run on generalists.
Hospitals are run by specialists. Financial systems are run by specialists. Chip design, aerospace engineering, industrial manufacturing. All of them depend on people who have spent decades mastering a narrow field.
Yet in AI, we have largely pursued the opposite path.
The past few years have been dominated by the race to build increasingly general models. A single session with an LLM allows you to write a Python web server, derive the Schrödinger equation, summarize War and Peace, translate between languages, generate marketing copy, and answer trivia about the history of the Mongol Empire, all within the same model.
That is impressive. But it is not how real systems work. In practice, the world runs on deep expertise, not shallow breadth. If that is true for humans, it will likely be true for AI as well.
At Cosine, we believe the next wave of progress will not come from making models ever more general. It will come from deeply specialized systems optimized for specific tasks.
Coding is one of the clearest places where this shift is already starting to happen.
The blind spot in AI coding
Coding capabilities have improved at an astonishing pace. Models can now generate production-ready code, debug complex logic, and complete entire tasks autonomously.
But most of this progress has been concentrated on a narrow slice of the software world.
Benchmarks and datasets overwhelmingly focus on languages like Python and JavaScript. These ecosystems dominate open-source repositories and developer tutorials, so they naturally dominate AI training and evaluation.
However, they represent the most visible parts of the modern software ecosystem rather than the specialized languages that underpin many enterprise and industrial systems.
Large enterprises run critical infrastructure on very different languages:
- COBOL: these systems, which constitute hundreds of billions of lines of COBOL code, underpin ~90% of financial transactions globally. At the same time, 65% of COBOL experts will retire by 2029.
- ABAP: the backbone of the SAP ecosystem used by more than 400,000 organizations worldwide, including the majority of Fortune 500 companies. This is especially pressing today as enterprises face the urgent need to migrate from legacy SAP ECC systems to S/4HANA before the 2027 maintenance deadline, a transition that requires modernizing vast amounts of legacy ABAP code.
- Rust: increasingly used for high-performance systems and infrastructure, and now adopted in major projects like the Linux kernel and critical cloud infrastructure.
- Verilog: the language used to design modern chips, forming the foundation of most digital hardware development across the semiconductor industry, which produces over a trillion chips annually.
In other words, some of the most critical systems in the global economy depend on languages that receive almost no attention in modern AI benchmarks.
Much of this code lives in specialized, legacy-heavy environments that are deeply out-of-distribution for modern models. Yet until now, no benchmark has seriously attempted to measure performance there.
Take SWE-bench, currently one of the most widely cited coding benchmarks. While it has helped drive progress in AI-assisted bug fixing, it also highlights the limitations of current evaluation approaches.
- First, it is almost entirely Python-focused, measuring performance on one of the most widely used languages in model training data rather than reflecting the broader landscape of real-world software systems.
- Second, it focuses almost exclusively on bug fixing in existing repositories, which represents only one narrow slice of what software engineers actually do. Real engineering work involves writing new modules, refactoring legacy systems, integrating APIs, and navigating poorly documented codebases.
- Third, a large portion of the benchmark is difficult or impossible to run reliably. Dependencies break, environments drift, and results can vary depending on subtle setup details. In practice, this makes a benchmark widely cited as a gold standard surprisingly difficult to reproduce in a clean, consistent way.
At Cosine, we therefore began asking a different question: How capable are modern AI models once you move beyond simple tasks in mainstream programming languages?
To answer that, we started benchmarking how leading models perform on a set of specialized languages that underpin large parts of the global software and hardware ecosystem.
Our approach
Benchmarking specialized languages requires a different approach from typical coding evaluations. These ecosystems often lack large open-source datasets and standardized evaluation tasks, which means the benchmarking infrastructure must be built from the ground up.
To address this, we developed a specialized data and evaluation pipeline designed to capture realistic development tasks across each language ecosystem. Our goal was to reflect the kinds of problems engineers actually encounter, rather than relying on synthetic or simplified prompts.
The process includes several stages:
- Curating language-specific repositories and codebases, including enterprise-oriented projects and domain-relevant libraries where available
- Extracting realistic coding tasks such as feature implementation, debugging, refactoring, and code completion scenarios
- Filtering and structuring tasks to ensure they are representative of real development workflows rather than trivial examples
- Normalizing prompts and task formats across models to ensure fair comparisons
- Building automated evaluation pipelines that verify syntactic correctness, compilation success, and functional behavior where possible
Where appropriate, we also incorporate unit tests, static analysis checks, and compilation-based validation to ensure that generated code is not only syntactically valid but functionally correct. This is particularly important for languages like Rust and Verilog, where correctness constraints and compilation semantics play a central role in real-world development.
The infrastructure was built internally at Cosine and draws on the same evaluation processes we use to develop and test our coding agents. This will allow us to expand the dataset continuously, add new languages, and incorporate more complex task categories over time.
Early results benchmarking specialist languages
For the first release, we have evaluated four languages (ABAP, Rust, COBOL, and Verilog) across three leading models (GPT-5.4, Kimi K2.5, and Devstral).
These results should be viewed as early signals rather than definitive rankings. The current benchmark evaluates models across ~200 tasks spanning implementation, debugging, and code completion scenarios in these languages. Over time, we plan to expand and mature this evaluation set, increasing the number and diversity of tasks, improving automated validation, and broadening coverage across specialist programming ecosystems.
That said, the initial results are revealing.
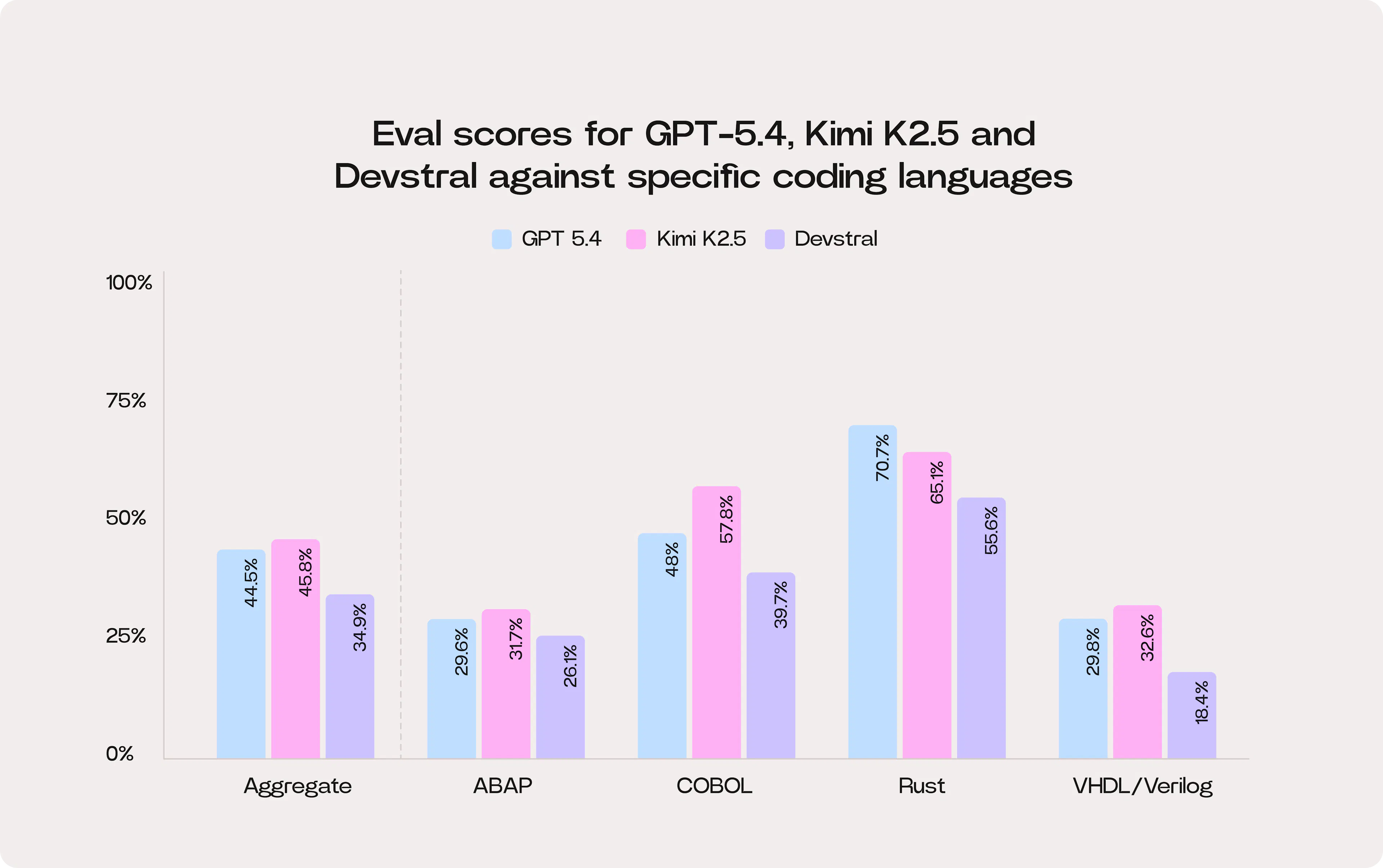
A few insights stand out immediately:
- Specialist languages remain hard for AI. Even the strongest models are far from perfect. Across the four languages, no model exceeds 50% aggregate pass rate. In other words, more than half of the tasks in these ecosystems still fail. The most difficult languages appear to be Verilog and ABAP, where pass rates cluster around 20-30%. This is likely due to a combination of smaller training corpora and highly specialized semantics.
- Different models excel in different ecosystems. Kimi K2.5 leads in COBOL, ABAP, and Verilog, while GPT-5.4 performs best in Rust. This reflects how model capabilities are heavily shaped by the training data they have been exposed to. Performance, therefore, on Python does not automatically translate to performance in other ecosystems.
- Bigger models are generally better, but at a cost. Devstral underperforms the other models on raw performance. Across the aggregate benchmark, it trails the other systems.
However, the picture looks different when you consider the model scale. Public information suggests that Kimi K2.5 has roughly 40x the parameter count of Devstral. The parameter count does not map perfectly to compute cost; factors such as architecture, context window, and number of layers also matter. But all else equal, you would expect a model that is 40x larger to be roughly an order of magnitude more expensive to run.
When you normalize performance against this scale difference, Devstral starts to look far more attractive for many tasks and deployment environments.
The road ahead
This analysis represents our early work benchmarking performance on specialist programming languages.
Our longer-term goal is to develop Niche-Bench: a comprehensive evaluation framework designed specifically to measure AI capabilities across niche and enterprise programming ecosystems.
Over time, we plan to expand this work by:
- Adding more specialist languages
- Increasing the number and diversity of tasks
- Introducing deeper evaluation categories such as debugging, refactoring, and large-scale system modifications
- Expanding coverage of enterprise development environments
Alongside this benchmarking effort, we are continuing to develop Cosine’s specialized coding agents, designed to deliver strong performance in these environments while remaining highly compute-efficient.
If you are interested in collaborating on this effort, contributing datasets, or helping shape the future of specialist coding benchmarks, we would love to hear from you. You can contact me at [email protected]