
 Share
Share
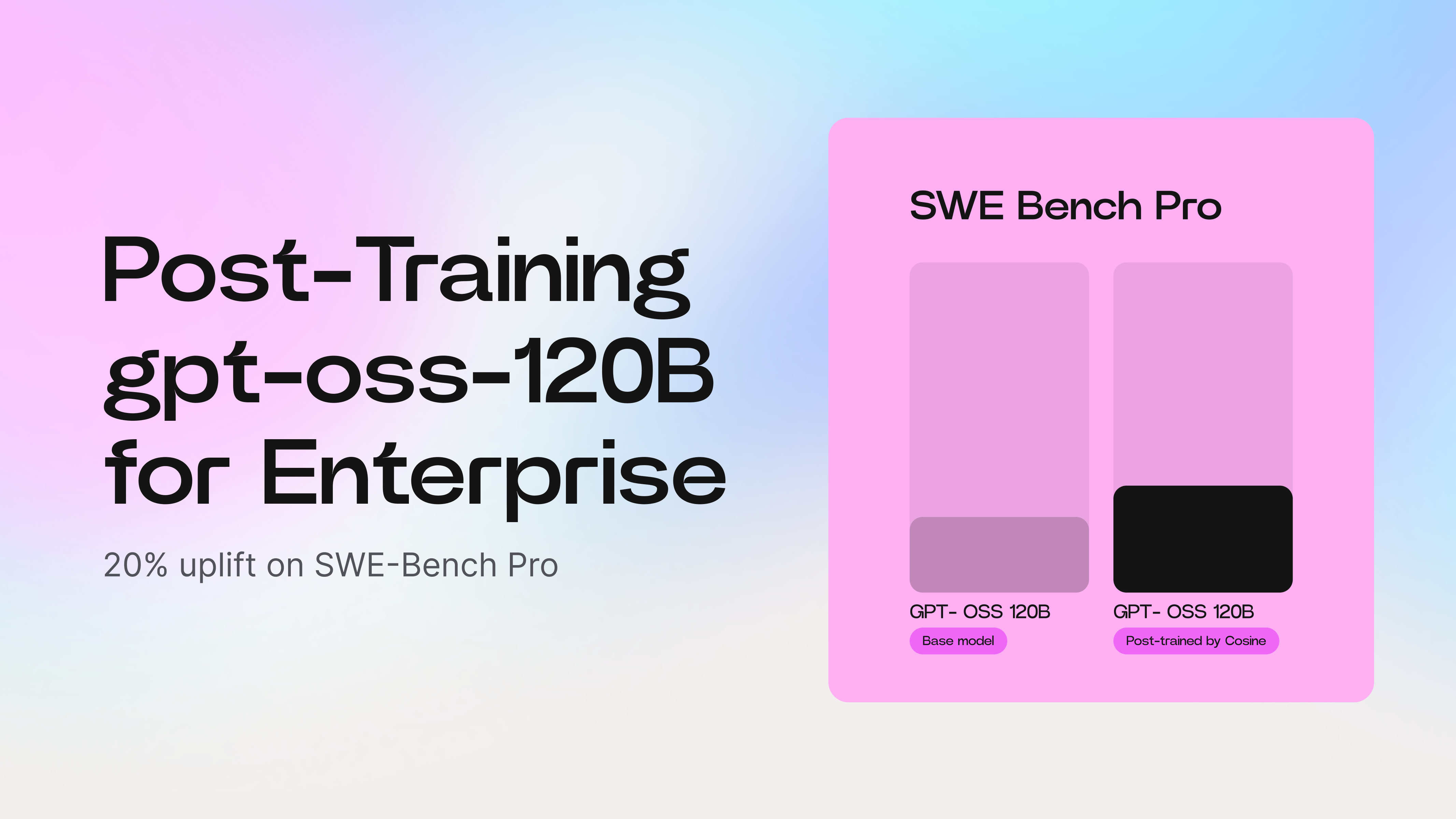
One of our large enterprise customers asked us to post-train OpenAI’s open-source gpt-oss-120B model to increase its effectiveness on software engineering tasks. In this post, we’ll share the approach we took and the early results: a 20% uplift in model performance versus the off-the-shelf baseline.
Why post-training?
Out of the box, even strong AI models often fall short on complex coding tasks. That’s especially true in enterprise environments with complex codebases, multiple languages, legacy systems, and internal frameworks.
Post-training helps address this shortfall by letting you optimise a base model’s weights for a specific end goal. For Cosine, this can involve further training on realistic code changes, internal repositories, and high-quality code reviews so the model learns to behave like a seasoned engineer inside an organisation’s actual stack.
Post-training is especially important for open-source models. Such models offer materially higher security and control, including truly air-gapped deployments with zero risk of data egress, which is critical for protecting customer data (PII), proprietary IP, and meeting tight regulatory and compliance requirements. Historically, though, they have lagged behind closed-source frontier models in accuracy. Post-training helps close that gap by aligning the model to real-world coding workflows and an organisation’s quality bar.
Cosine can post-train any open-source model, regardless of its size: from smaller Llama-70B–class models, through mid-sized gpt-oss-120B, up to larger models like Deepseek v3 and Kimi K2.
What post-training did we do?
One of our customers, a bulge-bracket investment bank, wanted to deploy Cosine in a fully air-gapped environment. That meant using an open-source model, deployed entirely within their own infrastructure.
However, their chosen base model (given GPU constraints) of gpt-oss-120B was not meeting the accuracy and reliability they needed when used off-the-shelf.
While we usually recommend larger models for the most demanding codebases, in this case, we took their selected OSS model and:
- Applied our post-training pipeline focused on software engineering tasks
- Used proprietary synthetic data generation tuned to enterprise code workflows
- Optimised specifically for quality, determinism, and robustness
Our post-training data is designed to mimic realistic, high-value scenarios: complex multi-file bug fixes in large monorepos, integration points between services, refactors, and edge cases that frequently occur in production systems. This lets us expose the model to far more “real-life” situations than it would do otherwise.
The result is a meaningful uplift in model quality while still meeting strict security, compliance, and deployment requirements.
The impact – and what’s next
On our first iteration, we improved gpt-oss-120B’s SWE-Bench Pro1 score by 20% compared to the baseline.
We’re confident that with further cycles of post-training and synthetic data generation, we can push gpt-oss-120B much closer to frontier-model performance - in other words, bringing state-of-the-art coding accuracy to fully air-gapped environments.
We’re also applying these same techniques to our frontier closed-source model, with results we’ll share in the new year.
Talk to us
If your organisation is exploring air-gapped, agentic coding assistants – AI systems that can read, modify, and test code autonomously – and you want to take a model of your choice and push it toward frontier-level performance, we’d love to talk.
—
1) SWE-Bench Pro is a standard benchmark for automated software engineering agents, measuring how well models can understand, modify, and fix real-world codebases.