

 @AlistairPullen
@AlistairPullen Before I share my learnings I need to give a little preamble to set the scene; A few weeks ago we launched the V1 of our product, and it both did and didn’t go according to plan. We were lucky enough to receive a great deal of exposure on Twitter and signups were flying in - the issue was two fold, our backend architecture was still very much in the ‘do things that don’t scale’ phase, and the general design of our product was incredibly inefficient. This early stress test highlighted that our current solution wouldn’t scale at all, and worst of all it’d be cripplingly expensive if we were to grow any further. We also had an office hours that week, where one of our group partners Tom Blomfield gave us the sage advice of stopping the onboarding of customers who were going to have a bad experience, as getting them to come back would be very tricky - we did this and it was good advice, I think we’d have disappointed a lot more people had we ignored it.
The source of this bank-breaking cost was the core of our product – our core functionality has always been allowing you to ‘search for what your code does, not what it is’, enabling queries like ‘Find where we initialize Stripe in React and add some logging’ which would never have been possible using existing search solutions. Our approach to solving this problem was to both index your entire codebase (something you have to do whatever your approach is) but to also pass each snippet we index into an LLM, and use that LLM to describe the code, then embedding that description. This gives you the ‘what the code does’ functionality. However, it turns out that this approach is a sure-fire way to burn through thousands of dollars worth of tokens and stay pinned to your rate limit.
At our peak we were processing nearly a quarter of a billion tokens per day
We considered trying to use a self-hosted LLM as an alternative, but the costs would also have been extremely high for the amount of traffic we were processing. After inspection, the token/cost breakdown between the models we were using pointed that the idea of having an LLM in the loop simply wasn’t feasible (it may well be in the future, but in the current incarnation of these LLMs, it isn’t). This meant we were at a crossroads, everything our product was predicated on was no longer viable so we had to figure out a way to get the same functionality, but without an LLM.
Our Solution
This solution isn’t groundbreaking, in fact it’s freely available on OpenAI’s cookbook, but I think it flies under the radar and I also think we had an interesting approach to it. The approach involves the creation of a custom matrix which you multiply all of your embeddings by to bias them to your usecase. The idea is that you can take extreme examples of both positive and negative classifications and ensure that your answers are better separated into those classifications.
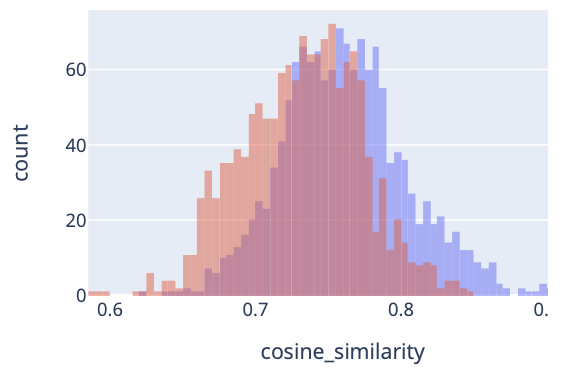
For example this is a graph of unoptimised embeddings for our usecase plotting cosine similarity: the red bars depict answers where the two vectors compared should be dissimilar/have a low cosine similarity, and the blue are pairs which should have a similarity value. As you can tell there is a huge amount of overlap which essentially equates to false-positives; instances where you are looking for one outcome but get the opposite.
After performing some training on examples and creating a bias matrix that we multiply all of our embeddings by we get this output:
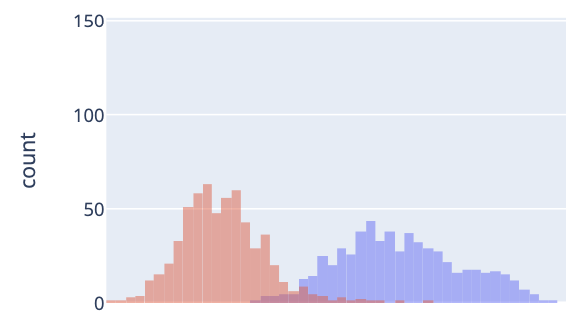
As you can see, the over lap has been drasitcally reduced, so the chances of you successfully matching an answer that is relevant are drastically higher.
Our implementation of this was interesting, because obviously we needed to essentially bias the embeddings to be able to interpret what the code was doing, so that if someone was looking for that functionality the bias would allow us to better find them, despite not having the LLM in the loop. To that end we did the following: gathered a corpus of open-source code snippets from Github, and then got an LLM to label them - in this isntance the labelling involved generating synthetic user queries which would map to each snippet, these queries had to be very varied both in syntax, grammar, and type of search. Once we had these snippets-query pairs, we passed them into the customize_embeddings notebook from OpenAI’s Github repo and trained the model. The results were far higher than I’d anticipated, with ~90% accuracy compared to the 61% we were achieving before hand. Using this solution the embeddings are now doing the job that the LLM was doing prior, but at no additional cost whatsoever – you still use the same embeddings API as before, you just perform a matrix multiplication on the embedding once you get it back from the API, then it’s biased to your usecase.
Some Tips
- In the cookbook example the notebook generates synthetic negatives of your data, i.e. the example pairs that shouldn’t match - it assumes that all of the pairs you input do match. The synthetics are generated by randomly pairing one half of a positive input pair with another pair, and assuming that the output will be dissimilar. The issue with this approach is that there may well be crossover between those randomly chosen input pairs, e.g. for us it might pair a synthetic question asking ‘where is the networking code’ with a code snippet form another pair which involves networking, but lables it as negative anyway. If you let these through you’ll still get a decent amount of false positives so it’s worth bearing in mind. We solved it by performing a cosine similarity on the random pair that was generated and ensuring that it was low, and assuming that it would be enough to ensure they weren’t that similar - it had a good effect.
- On larger datasets run the training in Google Colab with a GPU
- You can use an A100 and it speeds up the training process immensely.
I’m always happy to chat about this subject, you can find me on Twitter @AlistairPullen


