
 @AlistairPullen
@AlistairPullen I can vividly remember when I first played with OpenAI’s davinci-002 model back in mid-2022. It was the first time I’d been wowed by a piece of technology in a very long time, and like many, I was completely hooked. The first query I ever gave it was a simple “Hello” which it dealt with easily, but the second was to ask it how it would go about building an app idea I had at the time. The response truly blew me away, and set in motion what became Cosine a few months later. I built a very crude MVP which could take an app idea, figure out what needed to be done to construct it, and would then pass off each of the individual components to the codex model which would then write code from scratch.
Back then we had 4K token context windows and low rate limits, so the results were decidedly lacking: you couldn’t fit a meaningful amount if information in the window along side the instructions meaning we had to break everything up resulting in inevitable information loss, but it was immediately obvious that there was a tremendous amount of potential in utilising LLMs to perform massive tasks in the coding space. I’ve been talking about building a Genie-like product for a long-time now, I gave a talk about our plans at a UCL sponsored event on our plans, but at that time (late 2022) the technology was simply not in a place where we could credibly attempt to build it.

Presenting plans for Genie at the UCL AI event | 13th December 2022
Since then we’ve been chasing the dream of building something that can genuinely automatically perform end to end programming tasks with no intervention and a high degree of reliability - an artificial colleague. Genie is the first step in doing exactly that.
What is Genie?
Genie 1 is the best AI software engineer in the world by far - scoring 30% on the industry standard benchmark SWE-Bench we have beaten the previous SOTA scores from Amazon's Q and Factory's Code Droid (both scored 19% on SWE-Bench) by 56% and Cognition’s Devin (scored 13.8% on a small subset of SWE-bench) by 118%. However, as Devin only ran 500 out of the 2294 tasks on SWE-Bench, their comparable score is 3.44%.
Genie 1 is able to solve bugs, build features, refactor code, and everything in between either fully autonomously or paired with the user, like working with a colleague, not just a copilot. We’ve taken a completely different approach to the competition: we think that if you want a model to behave like a software engineer, it needs to be taught how a human engineer works. This approach is what has allowed us to excel at benchmarks but also in building a product that truly behaves like a human software engineer. We’ve designed new techniques to derive human reasoning from real examples of Software Engineers doing their jobs. Our data represents perfect information lineage, incremental knowledge discovery, and step by step decision making. Representing everything a human engineer does logically.
By actually training our models with this dataset rather than simply prompting base models which is what everyone else is doing, we have seen that we’re no longer just generating random code until some works, it’s tackling problems like a human.

Why Training?
Model intelligence is a bottleneck, and in the pursuit of general foundational models this will be the case until we reach some level of AGI. When general models are pushed to their limits on specialised workflows their flaws become evident rapidly, this is illustrated by the fact that GPT-4 scores a meagre 1.31% on SWE-Bench out of the box, and even when aided with an agentic loop it only manages 12-15%. Everyone working on this problem is butting up against the same limit of model intelligence, this is why we chose to train rather than prompt. It was obvious to us from the outset that if we were able to codify the human reasoning that developers had when solving problems we could start to produce an ever improving approximation of a human software engineer. This is where we’ve pioneered - making explicit what was previously implicit.
We’ve been working for just under a year on curating a dataset that uses development activity from real developers as a base, and then built upon that to forensically reconstruct the implied reasoning and decisions from it using a wide range of proprietary static and LLM powered heuristics. The beauty of this approach is: because we utilise LLMs very heavily in our information lineage pipeline, when those base LLMs get better, so does the quality of the data we can extract, making our eventual model even better. We cannot wait for superior foundational models as we know that with every release we can immediately leapfrog the performance of that model with our specialised dataset, rather than fearing the release of the next model as many wrappers do. Additionally, our dataset can immediately be ported to any model at anytime, meaning we can always move to the smartest base model of the time and reap those rewards very flexibly.
How do you build an AI engineer?
My thesis on this is simple: make it watch how a human engineer does their job, and mimic that process. In practice, however, getting such and then effectively utilising that data is extremely difficult, because essentially it doesn’t exist. Of course there is abundant data representing the artefacts of a developer’s work: commits, PR’s, issues etc. but none of these actually show the act of doing the work to any degree of fidelity that can be useful for training a model to truly behave like a software engineer.
Building the tools to create a dataset that does show this process is what we’ve been working on for the past year, and we’ve been able to run these tools at scale. Our data pipeline uses a combination of artefacts, static analysis, self-play, step-by-step verification, and fine-tuned AI models trained on a large amount of labelled data to forensically derive the detailed process that must have happened to have arrived at the final output. The impact of the data labelling can’t be understated, getting hold of very high quality data from competent software engineers is difficult, but the results were worth it as it gave so much insight as to how developers implicitly think about approaching problems. All of this is great, but being able to do it at a scale that could yield sufficient training data for such a model was a real challenge we had to solve.
One of the most important aspects of the entire endeavour is the base model – we are not a foundational model company, and we don’t want to become one. We have a very specific use case, and benefit heavily from the generalised world model that foundational models have, not to mention the generalisations that they make having read substantial amounts of raw source code in their pre-training. When we first embarked on this project the best thing we could train at the time was gpt-3.5-turbo-16k and we quickly realised that this model was heavily constrained by intelligence, but more importantly be context length. To have truly high quality outputs the model needs as much information as possible, and this simply wasn’t possible with that model. We were lucky to be allowed to train much longer context length models with OpenAI, and this was the first thing that really unlocked our ability to research this project further – so much has been learned, but the number one learning, and it sounds obvious, is that the data is absolutely everything.
You have to be obsessed with the data quality. The importance of surrounding factors like hyperparameters, or even in cases data quantity, pale in comparison relative to the data. We’ve learned so much with regard to data mixes in terms of language, task type, task length, and many more before we found a strong solution that we could rely upon, and truthfully we’re still experimenting heavily with these mixes as there is still a great deal of performance on the table.
Once we had our first model trained, we were able to use it in our data loop to perform self-improvement, and this has been the case for each subsequent version we’ve trained - the previous version of the model allows us to add signal to our data, and for us to teach the model to learn from mistakes it’s made and to fix them, this bootstrapping approach allowed us to teach the model how to cope with situations that can’t usually be found in the data, as most programming data online is in a ‘perfect’ state, i.e. it (usually) works and doesn’t contain any common errors. This is impossible to do with an untrained model, meaning many if not all existing solutions don’t benefit from it.
What comes next?
We’re going to continue to sprint towards our vision, we want to be able to spin up new colleagues in a tech team as simply as dragging a slider on a webpage. The idea of engineering resource no longer being a constraint is a huge driver for me, particularly since starting a company. The value of an AI colleague that can jump into an unknown codebase and solve unseen problems in timeframes orders of magnitude quicker than a human is self-evident and has huge implications for the world.
There is still so much to build, first and foremost I want to ensure that we strike the right balance of shipping real products that solve problems to users and cutting edge research that has gotten us this far. It is important to remember that despite the SOTA performance Genie has exhibited there is still substantial performance left on the table –the model is only our first iteration and is still by far the best in the world on SWE-bench. We’ve unequivocally proven that our approach is the best way to build this type of product and already know exactly how to take Genie to the next level. Most importantly, it is to continue our obsession and ground-breaking work with our dataset. We won’t simply just increase the dataset size but we will also give the models new abilities, increase the breadth of data and continue to invent and implement techniques that codify human behaviour, not just reasoning.
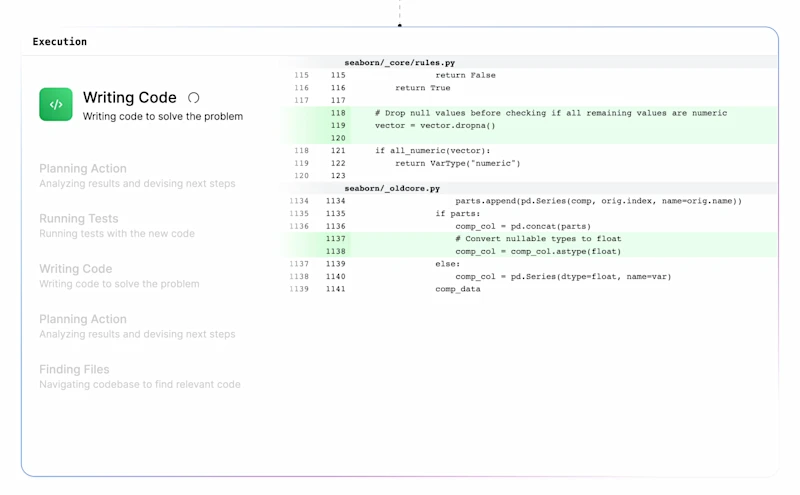
The downstream effects of this improved dataset for customers is world-changing, Genie will have greater proficiency with a wider range of programming languages, with a focus on proficiency on the latest and most widely used frameworks for each language to meet developers where, how and why they work.
We’re also going to expand our model portfolio into a family of models: smaller models capable of performing simpler tasks and larger models capable all tasks. Our unique advantage is that we can port our dataset(s) over to any model we like, meaning we can take our pick of whatever SOTA foundational models exist at any given point and immediately turn them into a Genie model. We also intend to context-extend one of the leading open source models and train it on a Genie dataset, our plan is always to have feet in both the OSS and closed-sourced communities, with further customisation being available on the open side. In the medium term we’re also going to pre-train extend a foundational model, in lieu of PEFT fine-tuning. We are not at that stage yet, but with the scale of dataset we anticipate on creating (a few trillion tokens worth), it makes more sense to train all parameters of the model and receive the benefits that are associated with that such as improved generalisation and ability to reconcile the specialised data with the existing pre-training data.
Whilst all of this model work is happening we’ll be shipping Genie constantly to customers – these work-streams will happen in parallel. Figuring out the optimal way to interact with an artificial team member is a novel problem and gives us immense scope for creativity and we’ll be getting all of the explicit and implicit feedback that we can from our customers as we progress in building an artificial general developer - AGD.
We truly believe that we’re able to codify human reasoning for any job and industry. Software engineering is just the most intuitive starting point and we can’t wait to show you everything else we’re working on. I
If you’d like to try Genie on your own projects you can apply for access right now.
Note
SWE-Bench has recently modified their submission requirements, now asking for the full working process of our AI model in addition to the final results -their condition to have us appear on the official leaderboard. This change poses a significant challenge for us, as our proprietary methodology is evident in these internal processes. Publicly sharing this information would essentially open-source our approach, undermining the competitive advantage we’ve worked hard to develop. For now, we’ve decided to keep our model’s internal workings confidential. However we’ve made the model’s final outputs publicly available on GitHub for independent verification. These outputs clearly demonstrate our model’s 30% success rate on the SWE-Bench tasks.