

 @AlistairPullen
@AlistairPullen We’ve been using the OpenAI foundational models for a while now at Buildt, they are amazingly powerful and this has been well documented across the internet, particularly with the advent of ChatGPT which has garnered 100x more attention than GPT-3 did before it. However with these models, and their applications to our problem: codebase search, understanding and augmentation; we found an obvious barrier: latency and cost. The larger models (particularly the davinci family) obviously produce the highest quality outputs, but are the slowest and most expensive to run.
For a good search experience you need speed, this is clear when you see Google taking 100s of milliseconds to index millions of webpages, and the story is the same for codebase search. We found that one of the largest time draws on a single search was the LLM layer producing an output (we use LLMs to augment our search to allow you to search for what your code is rather than what it does, e.g. ‘find me my slowest recursive functions’). According to Alex Graveley, one of the creators of Github’s Copilot, there is a 1% drop in completions for every additional 10ms of latency. This logic applies to search too so it was an immediate priority to move away from large models like davinci to smaller ones like ada and babbage.

Our solution is simple, generate a moderately sized corpus of completions made by davinci for a given task, and fine-tune a model like babbage to do the same task. If done correctly you can get near-identical completions (or at least 90% similarity) at a 40x lower price and around 4-5x better latency. You can go one-better than this, if you’re willing to invest a little time, you can introduce a human into the loop too: we recently did this to fine-tune a babbage model to competently identify characteristics in code, so I got ChatGPT to create me a basic web UI to allow us to easily review and improve the identification which davinci had carried out; fundamentally you’re never going to get like-for-like performance out of a smaller model so making the completions better than the model you’re trying to mimic means you’ll at least be closer when the training is complete.
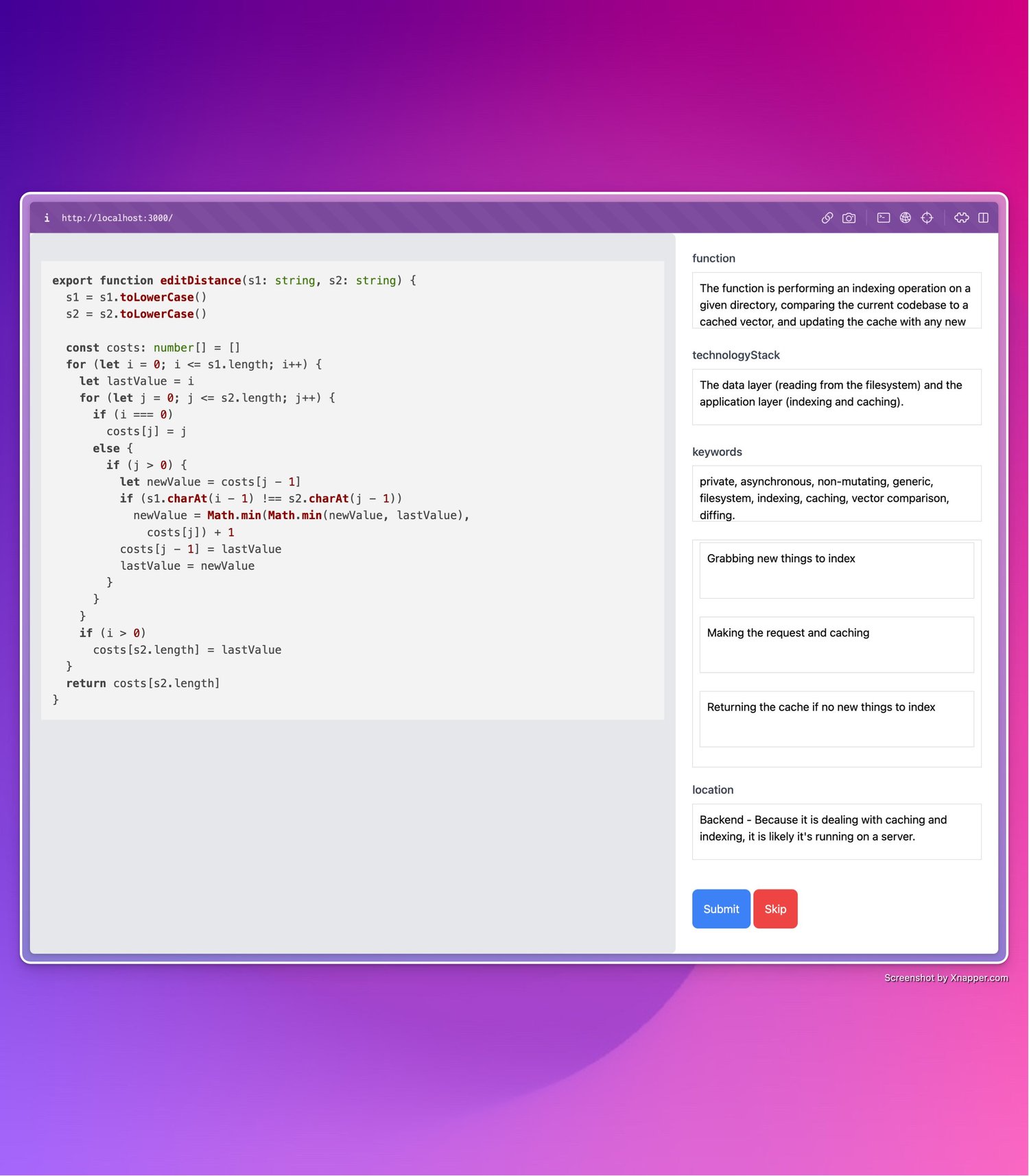
One of the questions I get the most about this technique is: how many examples do I need? The answer I’m afraid is ‘it depends’. As a rule of thumb, if you’re just trying to standardise the format of a prosaic output then you can get away with a couple hundred examples, if you’re doing logical reasoning, then you’re going to need at least 1000, and if you’re doing DSL work then multiple thousands. These sizes can often be a hurdle, but with the approach of using a larger model to produce the synthetic dataset it suddenly becomes a lot more manageable, particularly as those models get better.
There are many use cases for this approach; if you have a prompt which does the same job over and over, then you may as well use this technique to speed it up and make it cheaper. I’ve been asked about maintenance of this approach, particularly regarding what happens if the structure of the output you want changes. We built an internal finetuning pipeline which automates this entire process, you have your underlying davinci-003 prompt which we then use to generate n synthetic examples, which you then format and then pass into the OpenAI finetune API which will spit out a fine-tuned model. This way it’s a one-click operation to update a fine-tuned model if you want to change the output of your prompt.
I’m always happy to chat about this subject, you can find me on Twitter @AlistairPullen


