
 @AlistairPullen
@AlistairPullen Takeaways
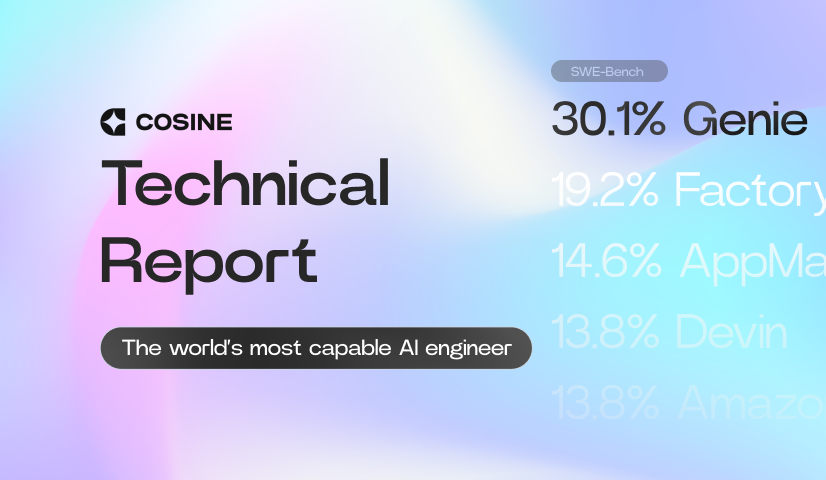
- Genie is the best software engineering model in the world scoring a state-of-the-art score of 30.08% on the SWE-Bench evaluation and 50.67% on SWE-Lite.
- Genie was trained on proprietary data that codifies human reasoning, representing perfect information lineage, incremental knowledge discovery, and step by step decision making derived from real examples of Software Engineers doing their jobs. As such it is taught how to problem solve logically exactly like a human engineer. Enabling Genie to perform far better than just oversampling with multiple out of the box LLMs.
By actually training Genie with this unique and complex dataset rather than simply prompting base models, which is what other AI wrappers do, we observed that Genie is tackling varied, highly contextual, and never before seen problems like a human.
Introducing Genie
Genie, the world’s most capable software engineering model according to SWE-Bench is the Cosine’s latest innovation in AI-driven development. It is designed to emulate the cognitive processes of human engineers, allowing it to tackle complex problems with unprecedented accuracy and efficiency.
Genie is the world’s first AI Software Engineering colleague trained on data that perfectly emulates the cognitive processes, logic and workflow of human engineers. Our proprietary techniques generates data that represents perfect information lineage, incremental knowledge discovery, and step by step decision making. This allows Genie to breakthrough the limitations faced by other AI software tools that are wrappers around foundational models with a few additional tools, such as a web browser or code interpreter. Genie is able to tackle unseen problems, iterate and test its output in the same logical way a human engineer would.
Genie is the world’s most capable software engineering AI according to SWE-Bench where we achieved a score of 30.07%, the industry standard for evaluating software engineering skills in AI models. This represents a 57% improvement over the previous best scores, held by Amazon’s Q and Code Factory at 19% (for context, OpenAI’s GPT4 scores 1.31%). This marks the highest score achieved by any company to date, and the largest single increase in SOTA score in the benchmark’s history. As part of this latest release we’ve observed Genie’s enhanced reasoning and planning capabilities to generalise well outside of the realms of software engineering and are committed to rigorous and careful red teaming efforts.
Evaluation
The core benchmark we’ve used to evaluate the model’s performance during its development was SWE-Bench, which is the best test of a model’s ability to solve software engineering problems, covering the disciplines of breaking down a problem, finding the relevant code, triaging that code, and implementing a working solution.
.png)
We were also able to benchmark the model’s ability to retrieve information for a task, specifically its ability to retrieve the correct parts of code files that it needs to make a change. This is one of the core components to an AI engineer – if the model can’t reliably and competently find the correct code to edit it’s ability to then edit code is underutilised. We measured this very simply by seeing how many lines that the model needed to find to complete the tasks were actually found, and Genie scored 64.27% by successfully retrieving 91,475 of 142,338 required lines. There is definitely huge room to improve here, and it was one of the aspects that was focussed on less than the ability to break down problems given the assumption that the code that was found was indeed correct.
Architecture
When we first started work on Genie we only had access to fine tune relatively short context window models in the 16-32k range. We did a lot of early exploration with these models, training them on substantial datasets >100m tokens, and quickly realised that the architecture we’d come up with had merit, but was fundamentally constrained by how much information was representable to the model at any given moment. After trying with various compression/chunking methodologies we concluded that the only way was to use a larger context model, although none were available to train at the time. Fortunately, a short while later we were able to secure the ability to train a long context OpenAI model, which was the break we needed to really see what Genie could do. For its most recent training run Genie was trained on billions of tokens of data, the mix of which was chosen to make the model as competent as possible on the languages our users care about the most at the current time. One of the largest areas we’re going to expand upon is this data mix, ideally we’d like to to match the true distribution of programming languages on the internet as closely as possible as we’d rather this wasn’t a purely opinionated choice.
| Language | Data Mix % |
|---|---|
| JavaScript | 21% |
| Python | 21% |
| TypeScript | 14% |
| TSX | 14% |
| Java | 3% |
| C# | 3% |
| C++ | 3% |
| C | 3% |
| Rust | 3% |
| Scala | 3% |
| Kotlin | 3% |
| Swift | 3% |
| Golang | 3% |
| PHP | 3% |
| Ruby | 3% |
| Example Type | Data Mix % |
|---|---|
| Feature Development | 25% |
| Bug Fixing | 20% |
| Refactoring | 15% |
| Minor Changes & Chores | 15% |
| Test Writing | 15% |
| Writing and Updating Documentation | 10% |
Genie was always designed to be ‘agentic’, although when we first dreamt up the idea back in late 2022 the term hadn’t really cemented itself in the industry. Fundamentally we wanted Genie to be able to react to what it was seeing and proceed in the most logical way, we needed a dataset that could represent this. One of the largest challenges to overcome was to ascertain the prerequisite information required to perform a task in an unknown codebase – it’s very rare that you can simply make changes to files in isolation without having a basic understanding of how the project works, as a result for every task we trained on we had to show the model the process of finding this prerequisite information first, so that it would not hallucinate code, and would produce solutions that were in line with how the codebase was already organised and operated. This is the tip of the iceberg when it comes to the work that was done to make as much implied information in a developer’s mind explicit, we have been obsessive over it and have already made inroads to building the next incarnation of this pipeline following our evaluation of the current Genie model.
In terms of Genie’s inference characteristics we wanted to keep things as simple as possible, the agentic loop is comprised of four main processes: planning, retrieval, code writing and code running. These alone are not new, most tools in this space will use a mix or all of these, however because Genie is trained to perform each of these tasks as a human would, rather than how a base LLM would, we’re able to extract so much more performance from the model.
One of the most substantial performance enhancer’s was our use of self-improvement in the training of the model. Much of the data that we were training on was in a ‘perfect’ state, because the vast majority of the time the code that is published by a human is in a working state for it to have been published. This meant that at first Genie had never really seen things go wrong, and it was actually quite poor at reacting to mistakes that it had made. Fortunately once we had the first iteration of Genie trained, we were able to use it to generate synthetic data that we injected into the dataset for our next model version – because we have the final states of the tasks for the training dataset we could use the previous version of Genie to come up with a solution, and then if it was wrong, we could use the final state to show it how to get from where it was to where it should be. Every time we repeated this process the initial candidate solution from Genie was stronger, and in many cases correct, and in the cases where it wasn’t the amount of correction we had to show the model in the dataset was much reduced.
The Future
We’re continuing our sprint towards revolutionising tech teams with Genie. Our primary focus is to balance shipping real products that solve users’ problems with the cutting-edge research that has driven our progress. Despite Genie’s impressive state-of-the-art performance, we know there’s untapped potential, and we’re committed to refining our dataset to enhance Genie’s capabilities. By broadening the data and introducing new abilities, Genie will become proficient in more programming languages and the latest frameworks, meeting developers exactly where they work.
We’re expanding our model portfolio to include smaller models for simpler tasks and larger models for complex challenges, leveraging our unique dataset. This allows us to convert any state-of-the-art foundational model into a Genie model. Our plans include context-extending an open-source model and pre-training extending a foundational model on our extensive dataset, aiming for improved generalisation and specialised data reconciliation. One of the most exciting developments is fine-tuning Genie on specific codebases, an enterprise feature that gives Genie perfect understanding of large, legacy codebases, even when written in less popular or proprietary languages. As we continue refining Genie, we’ll constantly ship updates to customers, optimising interaction with this artificial colleague and gathering valuable feedback. Our journey to codify human reasoning for any job starts with software engineering, and we’re eager to showcase our progress.
If you’d like access to genie you can apply for access right now.
Note
SWE-Bench has recently modified their submission requirements, now asking for the full working process of our AI model in addition to the final results -their condition to have us appear on the offical leaderboard. This change poses a significant challenge for us, as our proprietary methodology is evident in these internal processes. Publicly sharing this information would essentially open-source our approach, undermining the competitive advantage we’ve worked hard to develop. For now, we’ve decided to keep our model’s internal workings confidential. However we’ve made the model’s final outputs publicly available on GitHub for independent verification. These outputs clearly demonstrate our model’s 30% success rate on the SWE-Bench tasks.


