
 @AlistairPullen
@AlistairPullen The State of Play
I’ve been playing around lately with the idea of what comes after RAG. RAG is the defacto way of getting a model to pontificate on any topic of your choosing but has always felt like somewhat of a hack - you’re always going to be limited by the quality of your RAG pipeline, and the fundamental constraint of the model’s context window - if you have a lot of relevant information from RAG you may not even be able to fit it all in, even with the larger models like gpt4-32k.
Our entire project, like many others is predicated on RAG, and we’ve invested a huge amount of time into researching what the optimal ways of using it are, but many claims of LLMs understanding your corpus are somewhat undermined by the fact that they’re only able to access a small amount of it at any one time.
Innate Knowledge
There are certain things that are just easier to know than to look up, and in certain usecases (particularly ones where the underlying data you want to work on doesn’t change very frequently) it would make more sense for the model to just know the information rather than having to look it up.
In the open-source world this is a relatively trivial thing to do, you can easily take a corpus of data and perform a LoRA/QLoRA autoregressive finetune on it at which point the model has remembered that information and can be made to recall it at will at inference time. The main advantage of this approach is that you can just take unstructured data and have the model learn it - no prompt/completion pairs or instruction sets required.
The problem for many people who choose to use OpenAI as their main model provider is that you have to conform to their chat style prompting template, meaning you can’t just blast a bunch of data through the model because you don’t have a completion for it. This is where I found a slight loophole in the system, and it’s a technique that I’ve used with differing levels of success over the past few weeks. For clarity: this isn’t a production ready technique, in fact it’s a bit of a hack, but it does work and it’s a good way of getting a model to learn a corpus of data without having to use RAG. To anyone who regularly works and FT’s OSS models this technique will sound insane, but it’s a good way of getting around the limitations of the OpenAI API - I really hope that they add a way to do this natively in the future.
The (Hacky) Technique
It’s a very simple workaround, the main problem with the current FT API is that you need to create these message prompt/completion pairs. What my technique does is just to format the message so that the user portion of the input is the data or part of the data you want the model to learn, e.g. a page from a book or a movie review or whatever. The mandatory assistant response should always be the same rare single token, e.g. ± for instance, the token itself doesn’t actually matter so long as it’s unlikely for it to appear in the user portion of the input.
[
{
"role": "user",
"content": "<Part of your corpus that you want the model to 'remember'>"
},
{
"role": "assistant",
"content": "±"
}
]Now when you actually train this model you’ll see that the loss curve inevitably goes to zero and stays there because it’s just predicting the same single token every time.
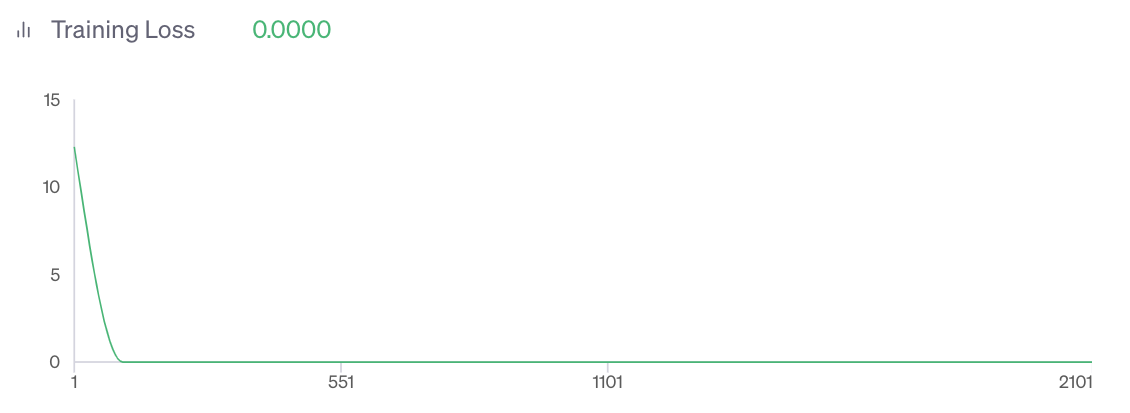
Now for the hack, if you use the fine tuned model out of the box you’ll always get the single token (±) back as your response, but now we’re going to apply a logit bias to completely ban this token from being predicted. This means that the model will have to predict something else, and then the data that it’s just been trained on will be available for it to comment on/use in its answer.
{
... // chat request config
"logit_bias": {
"38121": -100 // the token id of the single token we used in the assistant response
}
}NB: Sometimes you’ll see the model try to get around this bias by predicting different tokens that are close to the one you’ve chosen, e.g. +- or ± - you can just add these to the bias as well.
Results
This technique is ok, and obviously isn’t as good as a real autoregressive finetune, but in the absence of that it’s all we’ve got on the closed-source OpenAI side of things. I’ve had some success with it, but it can be very hard for the model to be steered to always refer to the data it’s just learned, but you can get around this with some very stern prompting, as well as the inclusion of some keywords/tokens as headers before your data in your dataset that you can then include in your prompt to try to bias it toward that information. I’m sure with enough iteration you could make this work in a production scenario, but for us and probably many others currently it makes more sense to go down the open source route.
I do firmly believe that for many of the current generation RAG powered AI applications the movement towards a more innate knowledge based approach is the way forward, and I’m excited to see what the future holds for this area of research and we’ll definitely be working it into Cosine as soon as we can.
You can find me on Twitter @AlistairPullen, and you can download the Cosine VS Code extension here and try out the demo on our website here.


